Optimisation Join
L'optimisation Join accélère l'exécution des mappages de données dans lesquels de grands ensembles de données sont filtrés ou joints.
L'optimisation Join fonctionne en éliminant les boucles imbriquées qui se produisent de manière interne lors de l'exécution d'un mappage. Une boucle imbriquée se produit lorsque le mappage itère chaque item d'un ensemble autant de fois qu'il y a des items dans un second ensemble. Veuillez noter qu'il est normal pour le moteur d'exécution* de mappage d'effectuer des boucles (itérations) sur plusieurs séquences d'items, du fait de sa conception. Lorsque des boucles indépendantes imbriquées se produisent (c'est à dire, des boucles qui itèrent sur d'autres boucles), le mappage peut bénéficier de l'optimisation join, qui pourrait réduire considérablement le temps requis pour exécuter le mappage. Les boucles imbriquées sont à peine visibles lorsque vous exécutez les mappages où les données d'entrée ne sont pas significativement plus grandes ; néanmoins, cela peut devenir un défi en cas de mappages qui traitent les fichiers ou les bases de données qui consistent en un très grand nombre d'enregistrements.
* Le moteur d'exécution d'un mappage peut être MapForce, MapForce Server, ou un programme C#, C++, ou Java généré par MapForce. L'optimisation Join est disponible exclusivement dans MapForce Server Advanced Edition.
Pour concevoir MapForce Server en tant qu'un moteur d'exécution cible, cliquer sur la touche BUILT-IN ( |
 ) dans la barre d'outils de MapForce. Cela permettra de vous assurer que votre mappage bénéficie de la plupart des fonctions disponibles. Si vous choisissez un autre langage de transformation, certaines fonctions MapForce peuvent ne pas être prises en charge dans ce langage.
) dans la barre d'outils de MapForce. Cela permettra de vous assurer que votre mappage bénéficie de la plupart des fonctions disponibles. Si vous choisissez un autre langage de transformation, certaines fonctions MapForce peuvent ne pas être prises en charge dans ce langage.
Comme indiqué ci-dessus, le but principal de l'optimisation join est d'adresser des boucles imbriquées de manière efficace. À présent, observons comment les boucles imbriquées se produisent.
Habituellement, des boucles imbriquées se produisent lorsque le mappage contient au moins un composant Join, et que le mode SQL JOIN** n'est pas possible.
** Lorsque certaines conditions sont remplies dans MapForce, les mappages peuvent permettre un mode d'exécution spécial appelé "SQL Join mode" (cela est uniquement applicable si le mappage lit les données provenant d'une base de données). Lorsque les données sont jointes de cette manière, l'opération join est effectuée par la base de données (c'est à dire qu'un SQL JOIN se produit), et cela élimine le besoin des boucles imbriquées dans le moteur d'exécution du mappage. Pour plus d'informations concernant le SQL Join, veuillez vous référer à la documentation MapForce (https://www.altova.com/fr/documentation.html). |
Par exemple, l'image ci-dessous montre un mappage (conçu avec Altova MapForce) qui combine des données provenant de deux fichiers XML utilisant un composant Join. Sur l'ordinateur sur lequel MapForce est installé, ce mappage est disponible sous le chemin suivant : ..\Documents\Altova\MapForce2026\MapForceExamples\Tutorial\JoinPeopleInfo.mfd. Certaines données concernant les personnes sont uniquement disponibles dans le premier fichier XML (Email, Phone), alors que d'autres données sont disponibles uniquement dans le second fichier XML (City, Street, Number). Le but du mappage est d'écrire dans le fichier XML cible les données fusionnées de toutes les personnes à savoir que FirstName et LastName correspondent dans les deux structures de source.
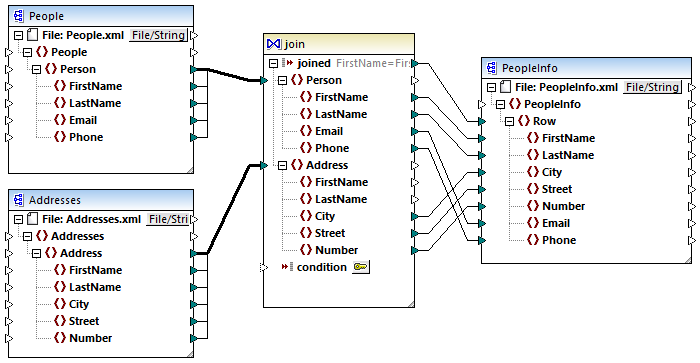
JoinPeopleInfo.mfd
Dans MapForce, un composant join jumelle des items dans deux ensembles conformément à des conditions personnalisées, qui implique la comparaison de chaque item dans l'ensemble 1 avec chaque item dans l'ensemble 2. Le nombre total des comparaisons représente la jointure croisée (produit cartésien) des deux ensembles. Par exemple, si le premier ensemble contient 50 items, et si le second ensemble contient 100 items, un total de 5000 (50 x 100) comparaisons se produiront. Dans le mappage ci-dessus, les ensembles qui sont comparés correspondent à tous les items d'instance des deux structures XML connectées au composant Join.
Note : Attention, ne pas confondre l'optimisation join (une fonction de MapForce Server Advanced Edition) avec les composants Join (une fonction de MapForce). Pour plus d'information concernant les composants Join, veuillez vous référer à la documentation MapForce (https://www.altova.com/fr/documentation.html).
Comme on peut s'y attendre, d'un point de vue de la performance, les mappages qui contiennent des boucles imbriquées nécessitent plus de temps pour être exécutés. Imaginez une situation où les deux ensembles joins contiennent des millions d'enregistrements. Cela peut facilement affecter la performance, et c'est là que l'optimisation join est utile. Très généralement, l'optimisation join se comporte comme un moteur de base de données qui est optimisé à consulter (index) de très grands ensembles de données. À part cela, comme illustré par le mappage ci-dessus, l'optimisation join ne traite pas uniquement avec des données provenant des bases de données. L'optimisation join élimine les boucles imbriquées quel que soit le type de données, en générant, lorsque cela est possible, des tables de consultation internes qui sont requises lors de l'exécution du mappage. Cela améliore de manière considérable la performance de mappage et finalement de réduire le temps requis pour exécuter le mappage.
Note : Lorsque l'optimisation join se produit, l'exécution du mappage prend moins de temps mais nécessite généralement plus de mémoire. Sachez que les profils d'utilisation de la mémoire dépendent de plusieurs facteurs complexes ; c'est pourquoi le comportement observé peut différer selon le cas.
L'optimisation join peut accélérer non seulement des mappages avec des joins, mais aussi ceux qui utilisent des composants de filtre. Dans MapForce, un filtre traite une séquence d'items (c'est à dire, il contrôle une condition booléenne donnée pour chaque instance de l'item connecté à l'entrée nœud/ligne). Si la condition booléenne est connectée à une fonction qui, à son tour, doit itérer sur une autre séquence d'items et si le contexte de mappage l'exige, une situation similaire à un join se produit. Si le filtre doit effectuer une comparaison croisée de chaque item dans deux ensembles, il se qualifie pour l'optimisation join.
Pour que le mappage puisse bénéficier d'une optimisation join, il doit être exécuté par MapForce Server Advanced Edition. Pour exécuter un mappage avec MapForce Server Advanced Edition, l'ouvrir dans MapForce, et le compiler dans un fichier d'exécution de mappage (.mfx) en utilisant la commande de menu Fichier | Compiler vers Fichier d'exécution MapForce Server. Ensuite exécuter le fichier .mfx en utilisant une méthode API dans le langage de votre choix ou bien la commande run de l'interface de ligne de commande (voir aussi Le principe de base).