Expresiones regulares
Al diseñar una asignación en MapForce puede usar expresiones regulares ("regex") en estos contextos:
•En el parámetro pattern de la función tokenize-regexp.
La sintaxis de las expresiones regulares en XSLT y XQuery se explican en Appendix F of "XML Schema Part 2: Datatypes Second Edition".
Nota: al generar código C++, C# o Java, las características avanzadas de la sintaxis de la expresión regular pueden variar ligeramente. Consulte la documentación regex de cada lenguaje para más información.
Terminología
Vamos a usar la función tokenize-regexp para analizar la sintaxis de las expresiones regulares. Esta función divide texto en una secuencia de cadenas con ayuda de las expresiones regulares. Para ello la función toma estos parámetros de entrada:
input | La cadena de entrada que va a procesar la función. La expresión regular que operará en esta cadena. |
pattern | La expresión regular pattern que se aplica. |
flags | Este parámetro es opcional y define las demás opciones (flags) que determinan cómo se interpreta una expresión regular; consulte "Flags" más abajo. |
En la asignación siguiente la cadena de entrada es "Altova MapForce". El parámetro pattern es un carácter de espacio y no se usan expresiones regulares flag.

Lo que ocurre es que se separa el texto cada vez que aparece el carácter espacio, por lo que el resultado de la asignación es:
<items> |
Observe que la función tokenize-regexp excluye los caracteres que coinciden del resultado. En otras palabras, el carácter espacio de este ejemplo se omite en el resultado.
El ejemplo anterior es muy básico, por lo que se puede conseguir el mismo resultado sin expresiones regulares, usando la función tokenize. En un caso real el parámetro pattern contendría una expresión regular más compleja. La expresión regular puede consistir en:
•Literales
•Clases de caracteres
•Intervalos de caracteres
•Clases negadas
•Metacaracteres
•Cuantificadores
Literales
Use literales para que los caracteres que coincidan sean idénticos a los que indica. Por ejemplo, si la cadena de entrada es abracadabra y pattern es el literal br, el resultado es:
<items> |
La explicación es que el literal br encontró dos coincidencias en la cadena de entrada abracadabra. Una vez omitidos esos caracteres del resultado, queda la secuencia de tres cadenas que se ve en el extracto de código.
Clases de caracteres
Si encierra un conjunto de caracteres entre corchetes ([ y ]) se crea una clase de caracteres. Solamente coincide uno de los caracteres dentro de esa clase, por ejemplo:
•El patrón [aeiou] busca cualquier vocal en minúsculas.
•El patrón [mj]ust busca "must" y "just".
Nota: el patrón distingue entre mayúsculas y minúsculas. Por ejemplo, "a" no encontrará "A". Para que el patrón deje de distinguir entre mayúsculas y minúsculas debe usar el parámetro flag i, véase más abajo.
Intervalos de caracteres
Use [a-z] para crear el intervalo comprendido entre dos caracteres. Solamente se encontrará uno de los caracteres en cada búsqueda. Por ejemplo, el patrón [a-z] busca cualquier carácter de la a a la z que esté en minúsculas.
Clases negadas
Si usa el acento circunflejo ( ^ ) como primer carácter tras el corchete de apertura, se niega la clase de caracteres. Por ejemplo, el patrón [^a-z] busca cualquier carácter que no esté en esa clases de caracteres, incluidas las líneas nuevas.
Buscar cualquier carácter.
Use el metacarácter punto ( . ) para buscar un solo carácter, sea cual sea (excepto líneas nuevas). Por ejemplo, . busca un solo carácter, sea cual sea.
Cuantificadores
Dentro de una expresión regular, los cuantificadores definen cuántas veces debe aparecer el carácter o la subexpresión anteriores para que la búsqueda obtenga resultados.
? | Busca cero o una coincidencia de la cadena precedente (la cadena es opcional) Por ejemplo, el patrón mo? Encuentra "m" y "mo". |
+ | Busca una o más coincidencias de la cadena precedente. Por ejemplo, el patrón mo+ Encuentra "mo", "moo", "mooo", etc. |
* | Busca cero o más coincidencias de la cadena precendente. |
{min,max} | Busca el número de repeticiones entre min y max.. P. ej. mo{1,3}encuentra "mo", "moo", and "mooo". |
Paréntesis
Los paréntesis ( y ) se usan para agrupar partes de la expresión regular. Se pueden usar para aplicar cuantificadores a una subexpresión (en vez de a un solo carácter) o con alternancia (véase a continuación).
Alternancia
La barra vertical | se usa con el significado "o". Se puede usar para buscar cualquiera de las distintas subexpresiones separadas por |. Por ejemplo, el patrón (horse|make) sense busca tanto "horse sense" como "make sense".
Flags
Estos parámetros opcionales definen cómo se debe interpretar la expresión regular. Para establecer las opciones se usan letras, que pueden estar en cualquier orden y se pueden repetir.
s | Si está presente, el proceso de búsqueda opera en el modo "dot-all".
Si la cadena de entrada input contiene "hello" y "world" en dos líneas diferentes, la expresión hello*world solamente encontrará resultados si se establece la marca flag s. |
m | Si está presente, el proceso de búsqueda opera en el modo multilínea.
En el modo multilínea el acento circunflejo ^ busca el principio de una línea, sea cual sea. Es decir, el inicio de una cadena entera y el primer carácter que aparece después del carácter de línea nueva.
El carácter de dólar $ busca el fin de una línea, sea cual sea. Es decir, el final de una cadena entera y el primer carácter que aparece antes del carácter de línea nueva.
El carácter de línea nueva es #x0A.. |
i | Si está presente, el proceso de búsqueda no distingue entre mayúsculas y minúsculas. Por ejemplo, la expresión regular [a-z] más la marca i encontrará todas las letras de la a-z y entre A-Z. 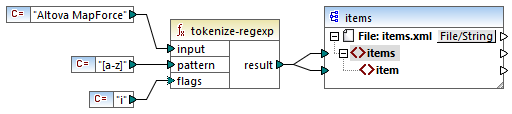 |
x | Si está presente, los caracteres de espacio en blanco se quitan de la expresión regular antes de iniciar el proceso de búsqueda. Los caracteres de espacio en blanco son #x09, #x0A, #x0D y #x20.
Nota: los caracteres de espacio en blanco sin expresiones de clases de caracteres no se eliminan (por ejemplo, [#x20]). |