XML-Vergleichsoptionen
Im Dialogfeld Vergleichsoptionen werden auf dem Register "XML" die Optionen angezeigt, die für Vergleiche von XML-basierten Dateien verwendet werden.
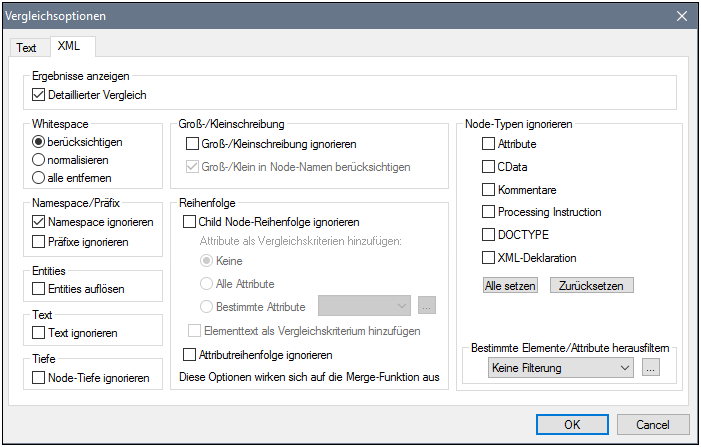
Ergebnisse anzeigen
Die Option Detaillierter Vergleich ermöglicht Ihnen, Unterschiede im Detail anzuzeigen oder die Anzahl der Unterschiede zu verringern (um schneller navigieren zu können). Wenn Sie diese Option deaktivieren, werden aufeinander folgende Nodes, die unterschiedlich sind, als ein einziger Node angezeigt. Dies gilt auch für aufeinander folgende Nodes auf unterschiedlichen hierarchischen Ebenen, wie z.B. einen Element-Node und seinen Child-Attribut-Node. Bitte beachten Sie, dass die Option "Detaillierter Vergleich" aktiviert sein muss, damit das Zusammenführen bzw. Exportieren von Unterschieden möglich wird.
Diese Einstellung kann nicht verwendet werden, wenn Datenbankdaten verglichen werden und der Spaltendatentyp XML ist.
Whitespace
Siehe Vergleichsoptionen für Whitespace-Zeichen.
Namespace/Präfix
Dieser Bereich enthält Optionen zum Ignorieren von Namespaces und Präfixen, wenn Sie nach Unterschieden suchen.
Entities
Wenn die Option Entities auflösen aktiviert ist, werden alle Entities im Dokument aufgelöst. Andernfalls werden die Dateien einschließlich Entities verglichen, wie sie sind.
Text
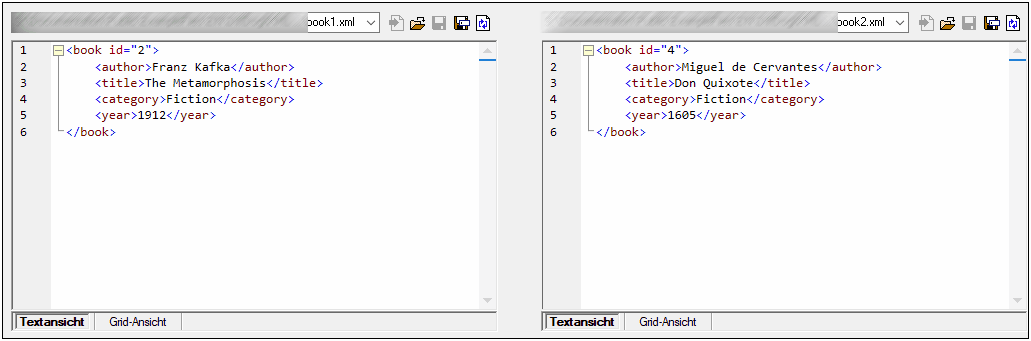
Bei Auswahl der Option Text ignorieren werden die Unterschiede in einander entsprechenden Text-Nodes nicht berücksichtigt. Es wird nur die XML-Struktur verglichen, nicht jedoch der Textinhalt der Tags. Diese Option ist nützlich, wenn Sie zwei XML-Strukturen miteinander vergleichen wollen und den eigentlichen Inhalt dabei außer Acht lassen möchten. Angenommen, das Kontrollkästchen Text ignorieren ist aktiviert. In diesem Fall werden die folgenden beiden XML-Dateien als identisch betrachtet (obwohl sich der Inhalt unterscheidet).
Tiefe
Wenn Node-Tiefe ignorieren aktiviert ist, gelten Elemente als identisch, ohne dass deren Tiefe berücksichtigt wird. Angenommen, das Kontrollkästchen Node-Tiefe ignorieren ist aktiviert. In diesem Fall gilt das Element <c> im unten gezeigten Vergleich als identisch, obwohl es rechts tiefer verschachtelt ist.
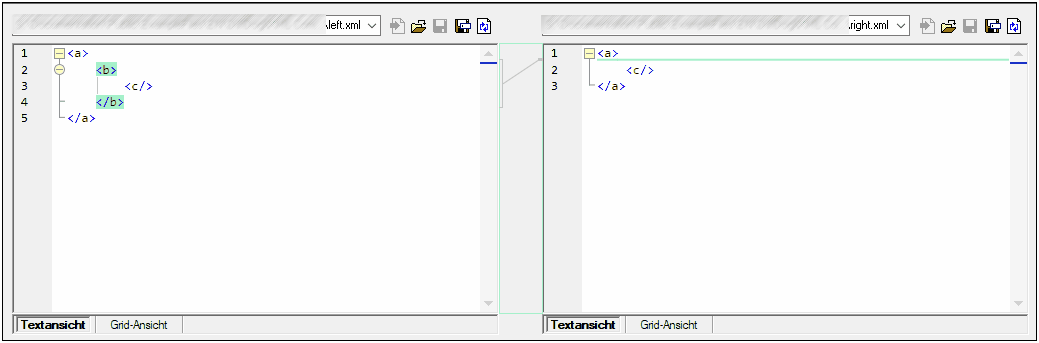
| Anmerkung: | Wenn das Kontrollkästchen Node-Tiefe ignorieren aktiviert ist, können Unterschiede nicht zusammengeführt und exportiert werden. |
Groß- und Kleinschreibung
Wenn die Option Groß-/Kleinschreibung ignorieren aktiviert ist, wird die Groß- und Kleinschreibung nicht berücksichtigt. Außerdem haben Sie die Option, die Groß- und Kleinschreibung in Node-Namen zu berücksichtigen oder zu ignorieren.
Reihenfolge
Wenn die Option Child Node-Reihenfolge ignorieren ausgewählt ist, dann wird die Position der Child-Nodes relativ zueinander nicht berücksichtigt, vorausgesetzt, dass die einzelnen Nodes innerhalb einer Ebene eindeutige Node-Namen haben. Solange in beiden Dokumenten in gleichrangigen Nodes ein Element-Node desselben Namens vorhanden ist, werden die beiden Node Sets als identisch betrachtet. Im folgenden Beispiel ist die Reihenfolge der Nodes <Name> und <FirstName> in der linken und rechten Datei unterschiedlich und wird als Unterschied gekennzeichnet, wenn die Option Child Node-Reihenfolge ignorieren deaktiviert ist.

Wenn Sie die Option Child Node-Reihenfolge ignorieren aktivieren, wird dieser Unterschied im Vergleichsfenster ignoriert.

Beachten Sie jedoch, dass DiffDog die Reihenfolge der Child-Nodes nur dann ignorieren kann, wenn die Node-Namen in einer bestimmten Node-Ebene eindeutig sind. Wenn ein Node mehrmals, z.B. mit verschiedenen Attributen, vorkommt, wird er, wenn er in einer unterschiedlichen Reihenfolge auftaucht, immer als nicht identisch mit einem Element desselben Namens und mit dem gleichen Attribute im verglichenen gleichrangigen Node Set betrachtet – selbst wenn die Option Child Node-Reihenfolge ignorieren aktiv ist. Wenn wir in unserem Beispiel verschiedene Attribute zum Node <Phone> hinzufügen, dann wird der Unterschied in der Reihenfolge der drei Varianten des Nodes <Phone> im Vergleichsfenster angezeigt selbst wenn das Kontrollkästchen Child Node-Reihenfolge ignorieren aktiviert ist.

Um die Reihenfolge von mehreren Child Nodes mit verschiedenen Attributen zu ignorieren, können Sie diese Attribute als Vergleichskriterien hinzufügen. In DiffDog stehen dazu zwei Optionen zur Verfügung: (i) Alle Attribute hinzufügen oder (ii) eine Liste bestimmter Attribute definieren, was in unserem Beispiel in beiden Fällen dazu führt, dass die <Phone> Nodes als identisch angezeigt werden. Wenn Sie die Option Bestimmte Attribute wählen, müssen Sie jedoch vorher eine entsprechende Attributgruppe definieren.

Es kann vorkommen, dass Child Nodes mehrfach vorkommen, die auch die gleichen Attribute aufweisen (z.B. eine Person mit mehr als einer Mobiltelefonnummer in unserem Beispiel). In der unten stehenden Abbildung wurde die Option Alle Attribute ausgewählt, es werden allerdings trotzdem noch Unterschiede angezeigt weil mehr als eine Mobiltelefonnummer angeführt ist.

In DiffDog können Sie in einem solchen Szenario das Kontrollkästchen Elementtext als Vergleichskriterium hinzufügen aktivieren. Wenn Elementtext, Wert des Attributs und Node-Name identisch sind und nur die Reihenfolge der Nodes unterschiedlich ist, werden keine Unterschiede angezeigt.

Beachten Sie, dass die Reihenfolge auch von der Zusammenführungsfunktion ignoriert wird, wenn die Option Reihenfolge ignorieren aktiv ist. Wenn die Option Child Node-Reihenfolge ignorieren deaktiviert ist, werden die Unterschiede in der Reihenfolge als Unterschiede markiert.
Des Weiteren steht die Option Attributreihenfolge ignorieren zur Verfügung. Sie gilt für die Reihenfolge der Attribute eines einzelnen Elements. Wenn Sie im obigen Beispiel die Option Attributreihenfolge ignorieren aktivieren, ignoriert DiffDog die Reihenfolge der Attribute im Node <Person>. Beachten Sie, dass die Reihenfolge von Attributen immer ignoriert wird, wenn das Kontrollkästchen Child Node-Reihenfolge ignorieren aktiviert ist. In der unten stehenden Abbildung sind sowohl das Kontrollkästchen Child Node-Reihenfolge ignorieren als auch das Kontrollkästchen Attributreihenfolge ignorieren deaktiviert.

Node-Typen ignorieren
Aktivieren Sie die Kontrollkästchen für die Node-Typen, die im Vergleich nicht berücksichtigt werden sollen. Zur Auswahl stehen die Optionen: Attributes, CDATA, Comments, Processing Instructions und DOCTYPE-Anweisungen und XML-Deklarationen.
Bestimmte Elemente/Attribute herausfiltern
Dient dazu Filter zu definieren, um festzulegen, welche Elemente und/oder Attribute nicht verglichen werden sollen. Die Gruppe von Elementen und/oder Attributen, die beim Vergleich nicht berücksichtigt werden sollen, werden in einem Filter definiert. Filter werden auf Anwendungsebene definiert, d.h. sobald ein Filter definiert wurde, steht er für jeden Vergleich zur Verfügung. Sie können auch mehrere Filter definieren. Bei den einzelnen Vergleichen können Sie den gewünschten Filter in der Auswahlliste "Bestimmt Elemente/Attribute herausfiltern" auswählen.