Merge/Split Data Elements
EDI segments often allow using multiple consecutive occurrences of the same data element. For example, this is possible for the N2 segment (Additional Name Information) of the 850 Purchase Order transaction set of the X12 standard. According to the specification, the N2 segment allows for two consecutive alphanumeric Name fields, one of which is mandatory and the other is optional (screenshot below).

Segments that allow multiple repeating instances of a particular data element have the mergedEntries attribute set for the relevant Data element in the .Segment file (highlighted yellow in code listing below). The .Segment file is originally stored in the MapForceEDI\<EDI_Standard> folder of your application folder.
<Segment name="TI" info="Transport Information">
<Data ref="F140" minOccurs="0" mergedEntries="2"/>
<...>
</Segment>
When you create or modify an EDI configuration, you can use a single node for all occurrences of a data element (merged entries) or split this data element into separate nodes (see below).
Approach 1: Use one node for all occurrences of a data element
In this approach, we use one node for all occurrences of a data element. By default, the F93 data element of the N2 segment is represented as a single node in the mapping (screenshot below). When you connect the F93 node to a target node, MapForce will create as many items in the target as there are repeating instances of F93 in the source. This follows the basic rule of MapForce connections: For each item in the source, create one item in the target.
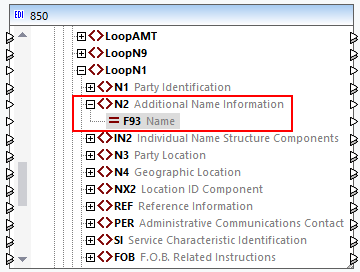
To make sure the F93 data element is represented as one node, open the X12.Segment file and check whether the mergedEntries attribute is set in the F93 data element of the N2 segment. In the code listing below, the mergedEntries attribute is set to 2. This means that the data element can have up to two consecutive occurrences in the EDI instance file, but the data element will appear as a single node in the mapping.
<Segment name="N2" info="Additional Name Information">
<Data ref="F93" mergedEntries="2"/>
</Segment>
Mapping data from a data element which has merged entries will create multiple duplicate elements in the target for each occurrence of this element. In our example, the N2 segment contains two consecutive occurrences of F93 (Michelle Butler and Mrs):
N2+Michelle Butler+Mrs'
Mapping data from such an EDI file would create the following output (notice the duplicate occurrences of <ContactName>):
<Customer>
<Number>123</Number>
<ContactName>Michelle Butler</ContactName>
<ContactName>Mrs</ContactName>
<CompanyName>Nanonull, Inc.</CompanyName>
</Customer>
Using this approach is suitable when each occurrence of the data element is not meaningful by itself, and you do not want a separate node for each occurrence. For example, a data element with multiple occurrences may store multiple line entries that make up an address. For such cases, the merged entries approach might be more useful than having individual nodes for each address line.
Approach 2: Split a data element into multiple nodes
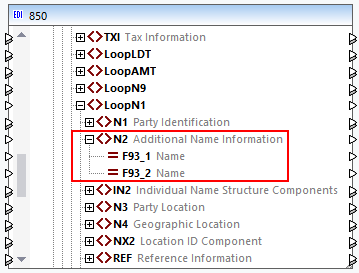
In this approach, we create multiple occurrences of a data element in the .Segment file. In this case, separate nodes will appear in the mapping for each occurrence of the data element. We have modified the X12.Segment file in such a way that the N2 segment has now two instances of the F93 data element called F93_1 and F93_2 (see code listing below).
<Segment name="N2" info="Additional Name Information">
<Data ref="F93" nodeName="F93_1"/>
<Data ref="F93" nodeName="F93_2" minOccurs="0"/>
</Segment>
This configuration creates two separate F93 nodes in the 850 component:
Using this approach is suitable when every occurrence of the data element is meaningful by itself and, consequently, you want to separate nodes in the mapping.