
このコマンドにより、構造化テキストファイルを XMLSpy へインポートし、直ちに XML フォーマットへ変換することができます。古いシステムからレガシーなデータをインポートするためにこの機能を利用することができます。以下にテキストファイル内のデータを XML ドキュメントとしてインポートする為の手順を記します。
| 1. | 「変換 | テキストファイルのインポート」を選択します。以下のダイアログが表示されます: |
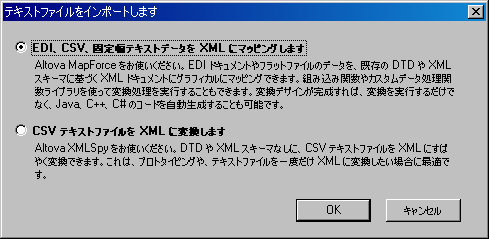
| 2. | 以下から選択を行います: |
•EDI、CSV、固定長テキストデータを XML へマッピング(このオプションを選択するには Altova MapForce がインストールされていなければなりません)
•CSV テキストファイルを XML へ変換
| 3. | 「OK」 をクリックします。テキストインポートダイアログが表示されます(以下のスクリーンショットを参照)。以下にこのダイアログの使用方法を記します。 |
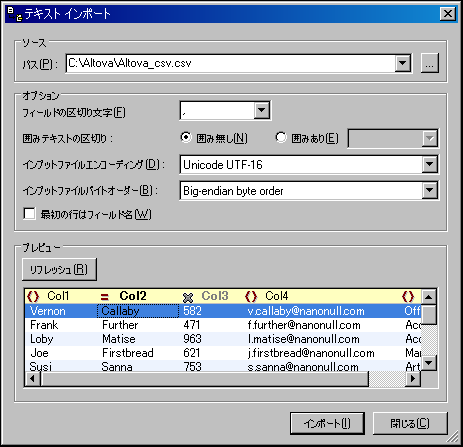
パス
インポートするファイルへのパスをパス テキストボックスへ入力するか、テキストボックスの右側にある参照ボタンを使用してファイルを選択します。ファイルが選択されると、XML ファイルのプレビューが、グリッドビュー形式でプレビュー ペインに表示されます。このダイアログにおけるオプションの変更は、プレビューへ直ちに反映されます。
区切り文字
テキストファイルをインポートするには、ファイル内部のカラムやフィールドを分割している区切り文字を指定する必要があります。標準的な行の区切り(CR、LF、または CR+LF)は <%XMLSPY% により自動的に識別されます。
文字列の引用符
レガシーなシステムからエクスポートされたテキストファイルの中には、数値データとの違いを明確にするために、文字列の値を引用句により囲んでいるものもあります。このような場合、ファイルの中で使用されている引用句を指定することで、データがインポートされた際にそれら引用句を自動的に削除することができます。
エンコード
データは(XML ドキュメントで通常使用される) ユニコード へ変換されるため、ファイル内で現在使用されているエンコーディングを指定する必要があります。
バイトオーダー
16ビットまたは32ビットのユニコード(UCS-2、UTF-16、または UCS-6)ファイルをインポートする場合、リトルエンディアンとビッグエンディアンバイトオーダーから選択を行うことができます。
最初の行はフィールド名
テキストファイル内にある最初の行にてフィールド名が記述されることもあります。この場合、このチェックボックスにチェックを入れてください。
プレビュー
プレビューペインでは、カラムヘッダーの名前をダブルクリックして編集を行うことで、カラム名を変更することができます。カラムヘッダーは、XML ドキュメントにおける要素または属性名となります。各カラムのヘッダーにあるアイコンをクリックすることで、カラムが要素なのか属性なのか、また XML ドキュメントにインポートするのかを選択することもできます。上のスクリーンショットでは、Col1 が要素、Col2 が属性としてインポートし、Col3 をインポートしないようにセットされています。
オプションの指定が終わったら、「インポート」をクリックします。インポートされたデータが XML ドキュメントに変換され、グリッドビューにて表示されます。