Requêtes Client
Une fois que RaptorXML+XBRL Server a été lancé en tant qu'un service, sa fonction peut être accédée par tout client HTTP capable de :
•utiliser les méthodes HTTP GET, PUT, POST et DELETE
•Définissez le champ de l'en-tête Content-Type
Un client HTTP facile à utiliserIl existe plusieurs clients web disponibles au téléchargement sur Internet. Le client web facile à utiliser et fiable que nous avons trouvé est RESTClient de Mozilla, qui peut être ajouté en tant qu'un plugin Firefox. Il est facile à utiliser, prend en charge les méthodes HTTP requises par RaptorXML et fournit une coloration syntaxique JSON suffisamment bonne. Si vous n'avez pas d'expérience préalable avec des clients HTTP, vous pouvez essayer RESTClient. Veuillez noter, néanmoins, que l'installation et l'utilisation de RESTClient est entièrement à vos risques. |
Une requête client typique consiste en une série d'étapes telles qu'affichées dans le diagramme ci-dessous.
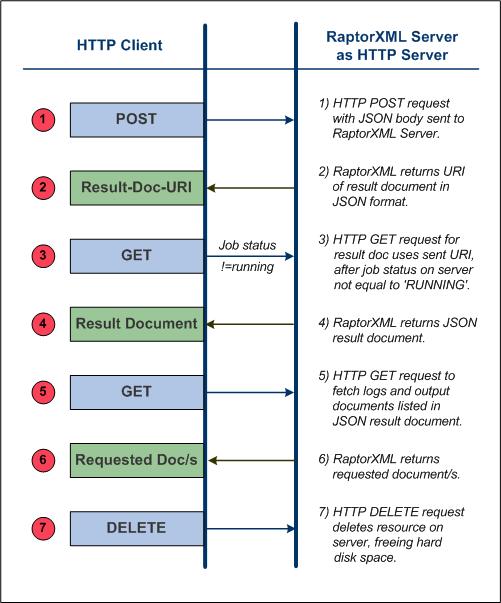
Les points importants caractérisant chaque étape sont notés ci-dessous. Les termes-clés sont gras.
1.Une méthode POST HTTP est utilisée pour faire une requête, le corps de la requête est en format JSON. La requête peut s'adresser à toute fonction de RaptorXML+XBRL Server. Par exemple, la requête peut être pour une validation, ou pour une transformation XSLT. Les commandes, arguments et options utilisés dans la requête sont les mêmes que ceux utilisés dans la ligne de commande. La requête est postée sur: http://localhost:8087/v1/queue, assumant que localhost:8087 est l’adresse de RaptorXML+XBRL Server (the adresse initiale du serveur). Une telle requête est appelée une tâche RaptorXML+XBRL Server .
2.Si la requête est reçue et acceptée pour le traitement par RaptorXML+XBRL Server, un document de résultat contenant les résultats de l'action de serveur sera créé une fois que le job a été traité. L'URI de ce document de résultat (le Result-Doc-URI dans le diagramme ci-dessus), est retourné sur le client. Veuillez noter que l'URI sera retournée immédiatement après que la tâche ait été acceptée (queued) pour le traitement et même si le traitement n'a pas été achevé.
3.Le client envoie une requête pour le document de résultat (en utilisant l'URI de document de résultat) dans une méthode GET sur le serveur. Si le traitement de la tâche n'a pas encore démarré ou n'a pas encore été achevé au moment de la réception de la requête, le serveur retourne un statut de Running. La requête GET doit être répétée jusqu'à ce que le traitement de la tâche ait été achevé et que le document de résultat ait été créé.
4.RaptorXML+XBRL Server retourne le document de résultat dans le format JSON. Le document de résultat peut contenir les URI des documents d'erreurs ou de sortie produits par le traitement de la requête d'origine par RaptorXML+XBRL Server. Les journaux d'erreur sont retournés, par exemple, si une validation a retourné des erreurs. Des documents de sortie primaire, comme le résultat d'une transformation XSLT sont retournés si une tâche de production de sortie est achevée avec succès.
5.Le client envoie les URI des documents de sortie reçu dans l'étape 4 par le biais d'une méthode GET HTTP vers le serveur. Chaque requête est envoyée dans une méthode GET séparée.
6.RaptorXML+XBRL Server retourne les documents requis en réponse aux requêtes GET effectués dans l'Étape 5.
7.Le client peut supprimer des documents non souhaités sur le serveur qui ont été générés en tant qu'un résultat d'une requête de tâche. Cela s'effectue en soumettant, dans une méthode DELETE HTTP, l'URI du document de résultat en question. Tous les fichiers sur disque liés à cette tâche sont supprimés. Cela comprend le fichier de document de résultat, tout fichier temporaire et les fichiers de document d'erreur et de sortie. Cette étape est utile pour libérer de l'espace sur le disque dur du serveur.
Les détails de chaque étape sont décrits dans les sous-sections de cette section.