Préparer les fichiers pour l'exécution de serveur
Un mappage conçu et prévisionné avec MapForce peut référer à des ressources se trouvant en dehors de l'appareil et du système d'exploitation actuels (comme des bases de données). Outre ce fait, dans MapForce, tous les chemins de mappage suivent des conventions de style Windows par défaut. De plus, l'appareil sur lequel MapForce Server est exécuté pourrait ne pas prendre en charge les mêmes connexions de base de données que l'appareil sur lequel de mappage a été conçu. C'est pour cette raison que les mappage exécutés dans un environnement de serveur nécessitent généralement une certaine préparation, en particulier si l'appareil cible n'est pas le même que l'appareil de source.
| Note : | Le terme "appareil source" renvoie à l'ordinateur sur lequel MapForce est installé et le terme "appareil cible" réfère à l'ordinateur sur lequel MapForce Server ou FlowForce Server est installé. Dans le scénario le plus simple, il s'agit du même ordinateur. Dans un scénario plus complexe, MapForce est exécuté sur un appareil Windows alors que MapForce Server ou FlowForce Server est exécuté sur un appareil Linux ou macOS. |
En règle générale, il est recommandé de s'assurer que le mappage soit validé avec succès dans MapForce avant de le déployer dans FlowForce Server ou de le compiler dans un fichier d'exécution MapForce Server.
Si MapForce Server est exécuté seul (sans FlowForce Server), les licences requises sont les suivantes :
•Sur l'appareil source, l'édition MapForce Enterprise ou Professional est exigée pour concevoir le mappage et le compiler dans un fichier d'exécution de serveur (.mfx).
•Sur l'appareil cible, MapForce Server ou MapForce Server Advanced Edition est exigé pour exécuter le mappage.
Si MapForce Server est exécuté sous la gestion FlowForce Server, les exigences suivantes s'appliquent :
•Sur l'appareil source, l'édition MapForce Enterprise ou Professional est exigée pour concevoir le mappage et le déployer sur un appareil cible.
•MapForce Server et FlowForce Server doivent tous deux être sous licence sur l'appareil cible. Le rôle de MapForce Server est d'exécuter le mappage ; le rôle de FlowForce est de rendre le mappage disponible en tant que tâche qui profite des fonctions telles que exécutions programmées ou exécution sur demande, exécution en tant que service Web, gestion d'erreur, traitement conditionnel, notifications d'e-mail, etc.
•FlowForce Server doit être activé et exécuté sous l'adresse et le port de réseau. Le service "FlowForce Web Server" doit être lancé et configuré pour accepter les connexions provenant des clients HTTP (ou HTTPS si configuré) et ne doit pas être bloqué par le pare-feu. Le service "FlowForce Server" doit aussi être démarré et exécuté à l'adresse et le port désigné.
•Vous devez disposer d'un compte utilisateur FlowForce Server avec les permissions d'un des conteneurs (par défaut, le conteneur /public est accessible à n'importe quel utilisateur authentifié).
Considérations d'ordre général
•Si vous comptez exécuter le mappage sur un appareil cible avec un MapForce Server autonome, tous les fichiers d'entrée référencés par le mappage doivent également être copiés dans l'appareil cible. Si MapForce Server est exécuté sous la gestion FlowForce Server, aucun besoin de copier les fichiers manuellement. Dans ce cas, les fichiers d'instance et de schéma sont inclus dans le pack déployé sur l'appareil cible.
•Si le mappage comprend des composants de base de données qui nécessitent des pilotes de base de données spécifiques, ces pilotes doivent aussi être installés sur l'appareil cible. Par exemple, si votre mappage lit des données provenant d'une base de données Microsoft Access, Microsoft Access ou Microsoft Access Runtime (https://www.microsoft.com/en-us/download/details.aspx?id=50040) doit aussi être installés sur l'appareil cible.
•Lorsque vous déployez un mappage sur des plateformes non-Windows, les connexions de base de données ADO, ADO.NET et ODBC sont modifiées automatiquement en JDBC. Les connexions SQLite natives et PostgreSQL natives sont préservées et ne nécessitent aucune autre configuration. Voir "Connexions aux bases de données" ci-dessous.
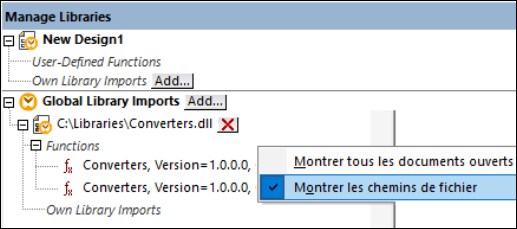
•Si le mappage contient des appels de fonction personnalisés (par exemple vers des fichiers .dll ou .class), Ces dépendances ne sont pas déployées avec le mappage, puisqu'ils ne sont pas connus avant l'exécution. Dans ce cas, les copier manuellement dans l'appareil cible. Le chemin du fichier .dll ou .class sur le serveur doit être le même que dans la fenêtre "Gérer bibliothèques" de MapForce, par exemple.
•Certains mappages lisent plusieurs fichiers d'entrée en utilisant un chemin de caractère générique. Dans ce cas, les noms de fichier d'entrée ne sont pas connus avant l'exécution et ils ne seront donc pas déployés. Pour que le mappage puisse être exécuté correctement, les fichiers d'entrée doivent exister sur l'appareil cible.
•Si le chemin de sortie de mappage contient des répertoires, ces répertoires doivent exister sur la machine cible. Sinon, une erreur sera générée lorsque vous exécuterez le mappage. Ce comportement est différent de celui sur MapForce, où des répertoires non existants sont générés automatiquement si l'option Générer une sortie dans les fichiers temporaires est activée .
•Si le mappage appelle un service web qui nécessite une authentification HTTPS avec un certificat client, le certificat doit aussi être transféré à l'appareil cible, voir .
•Si le mappage se connecte à des bases de données basées sur des fichiers comme Microsoft Access et SQLite, le fichier de base de données doit être transféré manuellement à l'appareil cible ou enregistré sous un répertoire partagé qui est accessible aussi bien à l'appareil source que cible et référencé à partir de cet endroit, voir "Bases de données basées sur fichier" ci-dessous.
Rendre les chemins portables
Si vous comptez exécuter le mappage sur un serveur, veuillez vous assurer que le mappage suive les conventions de chemin applicables et utilise une connexion de base de données prise en charge.
Pour rendre les chemins portables pour les systèmes d'exploitation non-Windows, utiliser des chemins relatifs et non pas absolus lors de la conception du mappage dans MapForce:
1.Ouvrir le fichier de design de mappage désiré (.mfd) avec MapForce sur Windows.
2.Dans le menu Fichier, choisir Paramètre de mappage, et décocher la case Rendre les chemins absolus dans le code généré si elle était cochée.
3.Pour chaque composant de mappage, ouvrir le dialogue Propriétés (en double-cliquant la barre de titre du composant, par exemple), et modifier tous les chemins de fichier d'absolus en relatifs. Ensuite, cocher la case Enregistrer tous les chemins de fichier relatifs au fichier MFD. Pour un plus grand confort, vous pouvez copier tous les fichiers d'entrée et les schémas dans le même dossier que le mappage lui-même, et les référencer uniquement par le nom de fichier.
Pour plus d'informations concernant la gestion des chemins relatifs et absolus pendant la conception des mappage, veuillez consulter la documentation MapForce .
Chose importante, MapForce Server et FlowForce Server prennent en charge tous les deux un soit-disant "répertoire de travail" par rapport auquel tous les chemins relatifs seront résolus. Le répertoire de travail est spécifié au moment de l'exécution du mappage, comme suit :
•Dans FlowForce Server, en éditant le paramètre "Répertoire de travail" de toute tâche.
•Dans MapForce Server API, par le biais de la propriété WorkingDirectory de l'API COM et .NET, ou par le biais de la méthode setWorkingDirectory de l'API.
•Dans la ligne de commande MapForce Server, le répertoire de travail est le répertoire actuel du shell de commande.
Connexions de base de données
Sachez que les connexions ADO, ADO.NET et ODBC ne sont pas prises en charge sur les appareils Linux et macOS. Ainsi, si l'appareil cible est Linux ou macOS, ces connexions sont converties en JDBC lorsque vous déployez le mappage sur FlowForce ou lorsque vous compilez le mappage sur un fichier d'exécution MapForce Server. Dans ce cas, vous disposez des options suivantes avant de déployer le mappage ou de le compiler dans un fichier d'exécution de serveur :
•Dans MapForce, créer une connexion JDBC vers une base de données .
•Dans MapForce, remplir les détails de connexion de la base de données JDBC dans la section "Paramètres spécifiques à JDBC" du composant de base de données .
Si le mappage utilise une connexion native à une base de données PostgreSQL ou SQLite, la connexion native est préservée et aucune conversion JDBC n'aura lieu. Si le mappage se connecte à une base de données basée sur fichier, comme Microsoft Access et SQLite, une configuration supplémentaire est nécessaire, voir "Bases de données basée sur fichier" ci-dessous.
L'exécution de mappage avec des connexions JDBC exige que le Java Runtime Environment ou le Java Development Kit soit installé sur la machine du serveur. Il peut s'agir soit d'un Oracle JDK soit d'un build open source comme Oracle OpenJDK.
•La variable d'environnement JAVA_HOME doit pointer vers le répertoire d'installation JDK. •Sur Windows, un chemin Java Virtual Machine trouvé dans le registre de Windows prendra la priorité sur la variable JAVA_HOME. •La plateforme JDK (64-bit, 32-bit) doit être la même que celle de MapForce Server. Sinon, vous risquez d'obtenir une erreur : "JVM est inaccessible". |
Pour configurer une connexion JDBC sur Linux ou macOS:
1.Télécharger le pilote JDBC fournit par le revendeur de base de données et l'installer sur le système d'exploitation. Veillez à choisir la version 32-bit si votre système d'exploitation fonctionne sur 32-bit, et la version 64-bit si votre système d'exploitation fonctionne sur 64-bit.
2.Définir les variables d'environnement à l'emplacement sur lequel le pilote JDBC est installé. Généralement, vous devrez définir la variable CLASSPATH, et éventuellement quelques autres variables. Afin de déterminer les variables d'environnement spécifiques que vous devez configurer, consulter la documentation fournie avec le pilote JDBC.
| Note : | Sur macOS, le système prévoit que toute bibliothèque JDBC installée se trouve dans le répertoire /Library/Java/Extensions. C'est pourquoi nous recommandons de déballer le pilote JDBC à cet emplacement ; sinon, vous devrez configurer le système pour chercher la bibliothèque JDBC dans le chemin dans lequel vous avez installé le pilote JDBC. |
Connexions Oracle Instant Client sur macOS
Ces instructions sont applicables si vous vous connectez à une base de données Oracle par le biais de Oracle Database Instant Client, sur macOS. Conditions préalables :
•Java 8.0 ou plus est installé. Si l'appareil Mac est exécuté avec une version Java précédente à Java 8, vous pouvez aussi vous connecter par le biais de la bibliothèque JDBC Thin for All Platforms et ignorer les instructions ci-dessous.
•Oracle Instant Client doit être installé. Vous pouvez télécharger l'Oracle Instant Client depuis la page de téléchargement officielle. Veuillez noter qu'il y a plusieurs packs Instant Client packages disponibles sur la page de téléchargement Oracle. Veuillez vous assurer de sélectionner un pack avec un prise en charge Oracle Call Interface (OCI), (par exemple, Instant Client Basic). De même, veillez à choisir la version 32-bit si votre système d'exploitation fonctionne sur 32-bit, et la version 64-bit si votre système d'exploitation fonctionne en 64-bit.
Une fois que vous avez téléchargé et déballé l'Oracle Instant Client, éditer le fichier de liste de propriété (.plist) envoyé avec le programme d'installation de manière à ce que les variables d'environnement suivantes pointent vers l'emplacement des chemins de pilote correspondants, par exemple :
Variable | Valeur échantillon |
CLASSPATH | /opt/oracle/instantclient_11_2/ojdbc6.jar:/opt/oracle/instantclient_11_2/ojdbc5.jar |
TNS_ADMIN | /opt/oracle/NETWORK_ADMIN |
ORACLE_HOME | /opt/oracle/instantclient_11_2 |
DYLD_LIBRARY_PATH | /opt/oracle/instantclient_11_2 |
PATH | $PATH:/opt/oracle/instantclient_11_2 |
| Note : | Éditer les valeurs d'échantillon ci-dessus pour correspondre aux chemins sur lesquels les fichiers Oracle Instant Client sont installés sur votre système d'exploitation. |
Bases de données basées sur fichier
Les bases de données basées sur fichier comme Microsoft Access et SQLite ne sont pas incluses dans le paquet déployé sur FlowForce Server ou dans le fichier d'exécution MapForce Server compilé. Ainsi, si l'appareil source et cible ne sont pas identiques, suivez les étapes suivantes :
1.Dans MapForce, cliquer avec la touche de droite sur le mappage et décocher la case Rendre chemins absolus dans le code généré.
2.Cliquer avec la touche de droite sur le composant de base de données sur le mappage et ajouter une connexion au fichier de base de données en utilisant un chemin relatif . Un moyen simple d'éviter les problème liés au chemin est d'enregistrer le design de mappage (fichier .mfd) dans le même répertoire que le fichier de base de données et de référer dans ce dernier depuis le mappage uniquement par le nom de fichier (en utilisant donc un chemin relatif).
3.Copier le fichier de base de données dans un répertoire sur l'appareil cible (appelons-le "répertoire de travail"). Nous vous conseillons de garder ce répertoire en tête, il sera nécessaire pour exécuter le mappage sur le serveur, tel que montré ci-dessous.
Pour exécuter ce type de mappage sur le serveur, suivre une des étapes suivantes :
•Si le mappage est exécuté par MapForce Server sous le contrôle de FlowForce Server, configurer la tâche FlowForce Server pour pointer vers le répertoire de travail créé précédemment. Le fichier de base de données doit résider dans le répertoire de travail. Pour consulter un exemple, voir Exposer une tâche en tant que service Web..
•Si le mappage est exécuté par le MapForce Server autonome dans la ligne de commande, changer le répertoire actuel en répertoire de travail (par exemple, cd path\to\working\directory) avant d'appeler la commande run de MapForce Server.
•Si le mappage est exécuté par l'API MapForce Server, définir le répertoire de travail par programme avant d'exécuter le mappage. Pour faciliter la tâche, la propriété WorkingDirectory est disponible pour l'objet MapForce Server dans l'API COM et .NET. Dans l'API Java, la méthode setWorkingDirectory est disponible.
Si les appareils source et cible sont des appareils Windows exécutés sur le réseau local, une autre approche est de configurer le mappage pour lire le fichier de la base de données depuis un répertoire partagé commun, comme suit :
1.Stocker le fichier de base de données dans un répertoire qui est accessible aussi bien par l'appareil source que cible.
2.Cliquer avec la touche de droite sur le composant de base de données sur le mappage et ajouter une connexion au fichier de base de données en utilisant un chemin absolu.
Ressources globales
Si un mappage inclut les références aux Ressources globales au lieu des chemins directs ou des connexions de base de données, vous pourrez également utiliser des Ressources globales du côté serveur. Lorsque vous compilez un mappage dans un fichier d'exécution MapForce Server (.mfx), les références aux Ressources globales resteront intactes afin que vous puissiez les fournir du côté serveur, lors de la marche du mappage. Lorsque vous déployez un mappage vers FlowForce Server, vous pouvez choisir en option s'il doit utiliser des ressources sur le serveur.
Pour que les mappages (ou des fonctions de mappage, dans le cas de FlowForce Server) puissent être exécutés avec succès, le fichier lui-même, le dossier ou les détails de connexion de base de données que vous fournissez en tant que Ressources globales doivent être compatibles avec le nouvel environnement de serveur. Par exemple, les chemins de fichier et de dossier doivent utiliser la convention Linux pour des chemins si le mappage sera exécuté sur un serveur Linux. De même, les Ressources globales définies en tant que connexions de base de données doivent être possibles sur l'appareil du serveur.
Pour plus d'informations, voir Ressources.
Packs de taxonomie XBRL
Lorsque vous déployez un mappage qui référence des Packs de taxonomie XBRL Packs de taxonomie XBRL sur FlowForce Server, MapForce collectionne toutes les références externes depuis le mappage et puis les résout en utilisant la configuration actuelle et les packs de taxonomie installés actuellement. S'il y a des références externes résolues qui pointes vers un pack de taxonomie, le pack de taxonomie est déployé avec le mappage. FlowForce Server utilisera ce pack (tel qu'il était pendant le déploiement) pour exécuter le mappage. Afin de réinitialiser le pack de taxonomie utilisé par FlowForce Server, vous devrez le modifier dans MapForce et de redéployer le mappage.
Veuillez noter que le catalogue root de MapForce Server influe sur la manière dont les taxonomies sont résolues sur l'appareil cible. Le catalogue root est trouvé sous le chemin relatif suivant dans le répertoire d'installation MapForce Server : etc/RootCatalog.xml.
Les packs de taxonomie qui ont été déployés avec un mappage sera utilisé si le catalogue root de MapForce Server ne contient pas déjà un tel pack qui est défini pour le même préfixe URL. Le catalogue root de MapForce Server a une priorité sur la taxonomie déployée.
Si MapForce Server est exécuté en autonomie (sans FlowForce Server), il est possible de spécifier le catalogue root qui devrait être utilisé par le mappage comme suit :
•Au niveau de la ligne de commande, il est possible en ajoutant l'option -catalog à la commande run.
•Dans l'API MapForce Server, appeler la méthode SetOption, et fournir la chaîne "catalog" en tant que premier argument, et le chemin vers le catalogue root en tant que second argument.
Si un mappage utilise des composants XBRL avec des bases de lien de table, le pack de taxonomie ou le fichier de configuration du pack de taxonomie doit être fourni au mappage lors de l'exécution comme suit :
•Au niveau de la ligne de commande MapForce Server, ajouter l'option --taxonomy-package ou --taxonomy-packages-config-file à la commande run.
•Dans l'API MapForce Server, appeler la méthode SetOption. Le premier argument doit être soit "taxonomy-package" ou "taxonomy-packages-config-file". Le second argument doit être le chemin actuel vers le pack de taxonomie (ou le fichier de configuration de taxonomie).