Example: Reading XML Documents (Java)
Tras generarse el código a partir del esquema de ejemplo se crea un proyecto de prueba Java junto con varias bibliotecas Altova secundarias.
Información sobre las bibliotecas Java generadas
La clase central del código generado es la clase Doc2, que representa el documento XML. Dicha clase se genera por cada esquema y su nombre depende del nombre del archivo de esquema (en nuestro ejemplo es Doc.xsd). Observe que esta clase se llama Doc2 para evitar conflictos entre los nombres de espacio de nombres. Como puede verse en el diagrama, esta clase aporta métodos para cargar documentos desde archivos, secuencias binarias o cadenas de texto (o para guardar documentos en archivos, secuencias y cadenas). Para ver una descripción de esta clase consulte la referencia de la clase com.[YourSchema].[Doc].
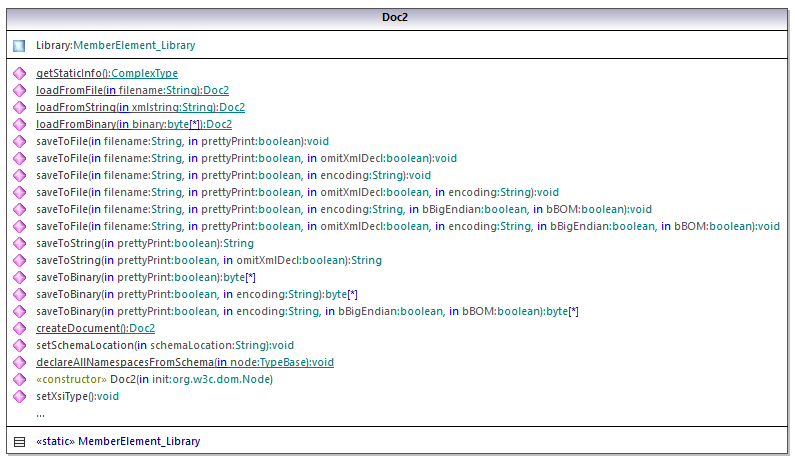
El miembro Library de la clase Doc2 representa la raíz real del documento.
De acuerdo con las reglas de generación de código mencionadas en el apartado Bibliotecas contenedoras de esquemas (Java), se generan clases miembro por cada atributo y por cada elemento de un tipo. En el código generado el nombre de dichas clases miembros va precedido por el prefijo MemberAttribute_ y MemberElement_ respectivamente. En el diagrama anterior puede ver ejemplos de dichas clases: MemberAttribute_ID y MemberElement_Author, que se generan a partir del elemento Author y del atributo ID de un libro respectivamente. Dichas clases permiten manipular los correspondientes elementos y atributos del documento XML de instancia mediante programación (operaciones anexar, eliminar, establecer valor, etc.). Para más información consulte la referencia de las clases com.[SuEsquema].[SuTipoEsquema].MemberAttribute y com.[SuEsquema].[SuTipoEsquema].MemberElement.
Como en el esquema DictionaryType es un tipo complejo derivado de BookType, esta relación también se refleja en las clases generadas. Como puede verse en el diagrama, la clase DictionaryType hereda la clase BookType.
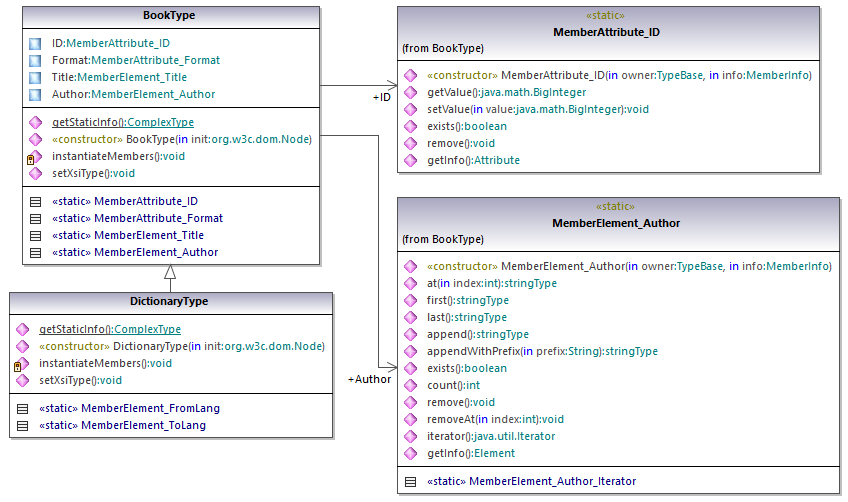
Si su esquema XML define tipos simples como enumeraciones, los valores enumerados están disponibles como valores Enum en el código generado. En el esquema utilizado en este ejemplo, el formato de los libros puede ser tapa dura, bolsillo, libro electrónico y audiolibro. Por tanto, en el código generado estos valores estarán disponibles a través de un Enum que es miembro de la clase BookFormatType.
Escribir un documento XML
1.En el menú File de Eclipse haga clic en el comando Import y seleccione Existing Projects into Workspace (Proyectos en el espacio de trabajo). Después haga clic en Next para continuar.
2.Junto a Select root directory (Seleccionar directorio raíz) haga clic en el botón Browse. Después seleccione el directorio donde generó el código Java y haga clic en Finish para finalizar.
3.En el explorador de paquetes de Eclipse expanda el paquete com.LibraryTest y abra el archivo LibraryTest.java.
Cuando cree prototipos de aplicaciones a partir de esquemas XML que cambien con frecuencia, a veces será necesario generar código una y otra vez en el mismo directorio para que los cambios en el esquema se reflejen inmediatamente en el código. Recuerde que la aplicación de prueba que se genera y las bibliotecas de Altova se sobrescribirán cada vez que genere código en el mismo directorio de destino. Por tanto, recuerde que no debe añadir código a la aplicación de prueba que se genera, sino que debe integrar las bibliotecas de Altova en el proyecto (ver Integrar bibliotecas contenedoras de esquemas). |
4.Edite el método Example() como se indica a continuación:
protected static void example() throws Exception { |
5.Compile y ejecute el proyecto Java. Si el código se ejecuta correctamente, se crea el archivo Library1.xml en el directorio del proyecto.
Leer un documento XML
1.En el menú File de Eclipse haga clic en el comando Import y seleccione Existing Projects into Workspace (Proyectos en el espacio de trabajo). Después haga clic en Next para continuar.
2.Junto a Select root directory (Seleccionar directorio raíz) haga clic en el botón Browse. Después seleccione el directorio donde generó el código Java y haga clic en Finish para finalizar.
3.Guarde el código que aparece a continuación en un archivo llamado Library1.xml en un directorio local (deberá referirse a la ruta de acceso del archivo Library1.xml desde el código).
<?xml version="1.0" encoding="utf-8"?> |
4.En el explorador de paquetes de Eclipse expanda el paquete com.LibraryTest y abra el archivo LibraryTest.java.
5.Edite el método Example() como se indica a continuación:
protected static void example() throws Exception { |
6.Compile y ejecute el proyecto Java. Si el código se ejecuta correctamente, el código de programa leerá el archivo Library1.xml y su contenido aparecerá en la vista de consola Console.
Leer y escribir elementos y atributos
El acceso a los atributos y elementos se consigue con el método getValue() de la clase de elemento o atributo miembro que se genera. Por ejemplo:
// valores de salida del atributo ID y del (primer y único) elemento title |
Para obtener el valor del elemento Title en este ejemplo concreto también se utilizó el método first(). Esto se debe a que este es el primer (y único) elemento Title de un libro. Cuando necesite seleccionar un elemento concreto de una lista por medio del índice, utilice el método at().
Para recorrer varios elementos utilice la iteración basada en índice o java.util.Iterator. Por ejemplo, puede recorrer los libros de la biblioteca de la siguiente manera:
// iteración basada en índice |
Para agregar un elemento nuevo utilice el método append(). Por ejemplo, este código anexa un elemento raíz Library vacío al documento:
// crear el elemento raíz <Library> y agregarlo al documento |
Tras anexar el elemento, puede establecer el valor de cualquiera de sus elementos o atributos con ayuda del método setValue().
// establecer el valor del elemento Title |
Leer y escribir valores de enumeración
Si el esquema XML define tipos simples como enumeraciones, los valores enumerados estarán disponibles como valores Enum en el código generado. En el esquema utilizado en este ejemplo el formato de un libro puede ser tapa dura, bolsillo, libro electrónico y audiolibro. Por tanto, en el código generado estos valores estarán disponibles a través de una Enum (véase el diagrama de la clase BookFormatType que aparece más arriba). Para asignar valores de enumeración a un objeto utilice código parecido a este:
// establecer un valor de enumeración |
Dichos valores de enumeración se pueden leer desde documentos XML de instancia de la siguiente manera:
// leer un valor de enumeración |
Cuando la condición IF no sea suficiente, cree un modificador para determinar cada valor de enumeración y procesarlo según corresponda en cada caso.
Trabajar con tipos xs:dateTime y xs:duration
Si el esquema desde el que se genera código utiliza tipos de hora y duración como xs:dateTime o xs:duration, estos tipos se convierten en clases nativas de Altova en el código generado. Por tanto, para escribir un valor de fecha o duración en el documento XML debe seguir estas instrucciones:
1.Construya un objeto com.altova.types.DateTime o com.altova.types.Duration.
2.Establezca el objeto como valor del elemento o atributo que necesita. Por ejemplo:
// establecer el valor de un atributo de tipo DateTime |
Para leer una fecha o duración de un documento XML:
1.Declare el valor de elemento (o atributo) como objeto com.altova.types.DateTime o com.altova.types.Duration.
2.Aplique formato al elemento o atributo que necesita. Por ejemplo:
// leer un tipo DateTime |
Para más información consulte la referencia de las clases com.altova.types.DateTime y com.altova.types.Duration.
Trabajar con tipos derivados
Si su esquema XML define tipos derivados puede conservar la derivación de tipos en los documentos XML que cree o cargue mediante programación. Tomando el esquema utilizado en este ejemplo, el fragmento de código que aparece a continuación explica cómo se crea un libro nuevo de tipo derivado DictionaryType:
// crear un diccionario (libro de tipo derivado) y rellenar sus elementos y atributos |
Recuerde que es importante establecer el atributo xsi:type del libro recién creado. Esto garantiza que el esquema interprete correctamente el tipo de libro a la hora de validar el documento XML.
El fragmento de código que aparece a continuación identifica un libro de tipo derivado DictionaryType en la instancia XML que se carga. Primero se busca el valor del atributo xsi:type del nodo book. Si el URI de espacio de nombres de este nodo es http://www.nanonull.com/LibrarySample y el prefijo de consulta URI y el tipo coinciden con el valor del atributo xsi:type, entonces sabemos que se trata de un diccionario.
// buscar el tipo derivado de este libro |