Solicitudes cliente
Tras iniciar RaptorXML Server como servicio, podrá acceder a sus funciones cualquier cliente HTTP que pueda:
•usar los métodos HTTP GET, PUT, POST y DELETE
•establecer el campo de encabezado Content-Type
Un sencillo cliente HTTPHay varios clientes web que puede descargar de Internet, pero el cliente web RESTClient de Mozilla es sencillo y fiable y se puede añadir como complemento de Firefox. Es fácil de instalar, es compatible con los métodos HTTP necesarios para trabajar con RaptorXML y ofrece funciones de color de sintaxis JSON. Si no tiene experiencia con clientes HTTP, recomendamos trabajar con RESTClient. No obstante, la instalación y el uso del cliente RESTClient corre por su cuenta y riesgo. |
Una solicitud cliente normal suele estar formada por varios pasos, como muestra el diagrama siguiente.
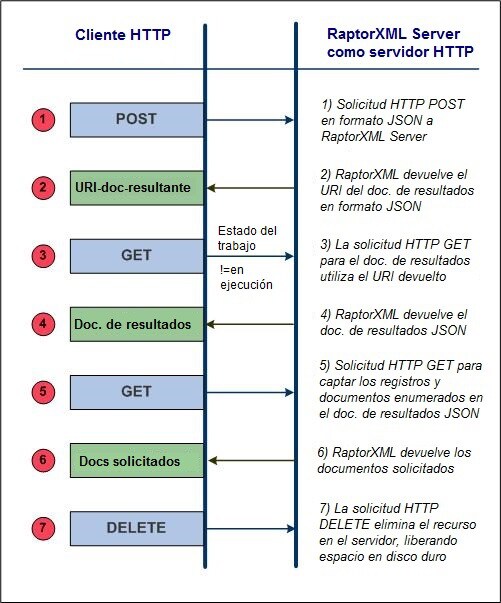
A continuación destacamos los aspectos más importantes de cada paso, señalando en negrita los términos más importantes.
1.Los métodos HTTP POST se utilizan para realizar una solicitud y el cuerpo de la solicitud está en formato JSON. La solicitud puede ser para cualquier función de RaptorXML Server. Por ejemplo, la solicitud puede ser para una validación o una transformación XSLT. Los comandos, los argumentos y las opciones utilizados en la solicitud son los mismos que los de la línea de comandos. La solicitud se envía a http://localhost:8087/v1/queue, si suponemos que localhost:8087 es la dirección de RaptorXML Server (la dirección inicial del servidor). Dicha solicitud recibe el nombre de trabajo de RaptorXML Server.
2.Si RaptorXML Server recibe y acepta procesar la solicitud, después de procesar el trabajo se genera un documento de resultados que contiene los resultados de la acción del servidor. El URI de este documento de resultados (ver URI-doc-resultante en el diagrama anterior), se devuelve al cliente. Recuerde que el URI se devolverá inmediatamente después de que se acepte procesar el trabajo (después de que se ponga en la cola) e incluso si el procesamiento no ha terminado.
3.El cliente envía al servidor una solicitud para el documento de resultados (usando el URI del documento de resultados) en un método GET. Si todavía no empezó el procesamiento del trabajo o si, cuando se recibe la solicitud, el procesamiento continúa, el servidor devuelve el estado En ejecución. La solicitud GET debe repetirse hasta que el procesamiento del trabajo haya finalizado y se haya creado el documento de resultados.
4.RaptorXML Server devuelve el documento de resultados en formato JSON. El documento de resultados puede contener los URI de los documentos de errores o de salida generados por RaptorXML Server al procesar la solicitud inicial. Por ejemplo, si una validación devuelve errores, se devuelve un registro de errores. Los documentos de salida principales, como el resultado de la transformación XSLT, se devuelven si el trabajo generador de resultados finaliza correctamente.
5.El cliente envía al servidor los URI de los documentos de salida recibidos en el paso nº4 a través de un método HTTP GET. Cada solicitud se envía en un método GET distinto.
6.RaptorXML Server devuelve los documentos solicitados en respuesta a las solicitudes GET realizadas en el paso nº5.
7.El cliente puede eliminar del servidor documentos no deseados generados como resultado de una solicitud de trabajo. Esto se hace enviando en un método HTTP DELETE el URI del documento de resultados en cuestión. Se eliminan del disco todos los archivos relacionados con dicho trabajo. Esto incluye el documento de resultados, los archivos temporales, los documentos de errores y los documentos de salida. Este paso es muy práctico si quiere liberar espacio en el disco duro del servidor.
Todos estos pasos se describen con más detalle en los apartados de esta sección.