Beispiel: Unterteilen von Datensätzen in Gruppen und Untergruppen
Das in diesem Beispiel beschriebene Mapping finden Sie unter dem Namen DividePersonsByDepartmentIntoGroups.mfd im Ordner <Dokumente>\Altova\MapForce2024\MapForceExamples\.
Das Mapping verarbeitet eine XML-Datei, die Mitarbeiterdatensätze einer fiktiven Firma enthält. Die Firma hat zwei Niederlassungen: "Nanonull, Inc." und "Nanonull Partners, Inc". Jede Niederlassung hat mehrere Abteilungen (departments) (z.B. "IT", "Marketing" usw.) und jede Abteilung hat einen oder mehrere Mitarbeiter. Ziel des Mappings ist es, unabhängig von der Niederlassung, aus jeder Abteilung Gruppen von maximal drei Mitarbeitern zu erstellen. Die Größe jeder Gruppe beträgt standardmäßig drei; dies sollte man jedoch bei Bedarf leicht ändern können. Jede Gruppe muss als separate XML-Datei mit dem Namen im Format "<Abteilungsname>_GruppeN" (z.B. Marketing_Group1.xml, Marketing_Group2.xml, usw.) gespeichert werden.
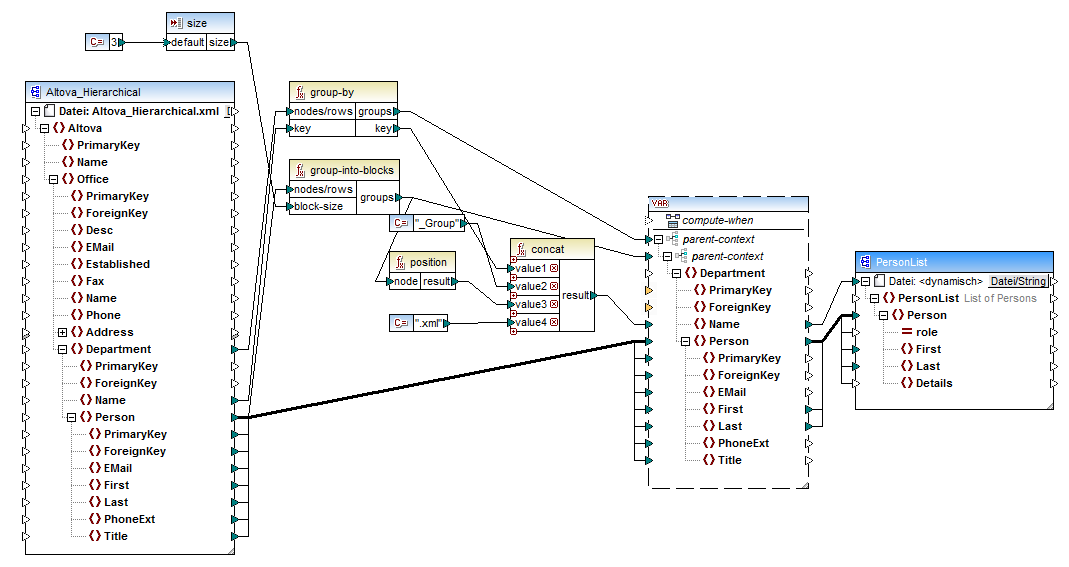
DividePersonsByDepartmentIntoGroups.mfd
Wie in der Abbildung oben gezeigt, wurden eine komplexe Variable sowie einige andere Komponententypen (hauptsächlich Funktionen) zum Mapping hinzugefügt. Die Variable hat dieselbe Struktur wie ein Department-Datenelement in der XML-Quelldatei. Wenn Sie mit der rechten Maustaste auf die Variable klicken, um ihre Eigenschaften anzuzeigen, sehen Sie, dass dafür dasselbe XML-Schema wie für die Quellkomponente verwendet wird und dass ihr Root Element Department ist. Wichtig ist vor allem, dass die Variable zwei ineinander verschachtelte parent-context-Datenelemente hat, mit denen sichergestellt wird, dass die Variable zuerst im Kontext jeder einzelnen Abteilung und anschließend im Kontext der einzelnen Gruppen in diesen Abteilungen berechnet wird (siehe auch Ändern von Kontext und Geltungsbereich von Variablen).
Das Mapping iteriert zuerst durch alle Abteilungen, um die Namen der einzelnen Abteilungen zu erhalten (diese Namen werden anschließend benötigt, um die Dateinamen für die einzelnen Gruppen zu erstellen). Zu diesem Zweck wird die group-by-Funktion mit dem Quelldatenelement Department verbunden und der Abteilungsname wird als Gruppierungsschlüssel bereitgestellt.
Als nächstes findet innerhalb des Kontexts der einzelnen Abteilungen eine zweite Gruppierung statt. Dabei ruft das Mapping die Funktion group-into-blocks auf, um die gewünschten Mitarbeitergruppen zu erstellen. Die Größe der Gruppen wird durch eine einfache Input-Komponente mit dem Standardwert "3" angegeben. Der Standardwert stammt aus einer Konstante. Um die Gruppengröße in diesem Beispiel zu ändern, muss man nur die Konstantenwert nach Bedarf anpassen. Sie können allerdings auch die "size" Input-Komponente ändern, sodass die Größe jeder Gruppe dem Mapping einfach als Parameter bereitgestellt wird, wenn das Mapping durch generierten Code oder mit MapForce Server ausgeführt wird. Nähere Informationen dazu finden Sie unter Bereitstellen von Parametern für das Mapping.
Als nächstes wird der Wert der Variablen an die XML-Zielkomponente PersonList geliefert. Die Dateinamen der einzelnen erstellten Gruppen wurden durch Verkettung der folgenden Teile mit Hilfe der concat-Funktion berechnet:
1.Der Name der jeweiligen Abteilung
2.Der String "_Group"
3.Die Nummer der Gruppe in der aktuellen Sequenz (z.B. "1", wenn es sich um die erste Gruppe in dieser Abteilung handelt)
4.Der String ".xml"
Das Ergebnis dieser Verkettung wird im Datenelement Name der Variablen gespeichert und anschließend als dynamischer Dateiname an die Zielkomponente weitergeleitet. Dadurch wird für jeden erhaltenen Wert ein neuer Dateiname erstellt. In diesem Beispiel werden anhand der Variablen insgesamt acht Gruppen erstellt, d.h. es werden bei Ausführung des Mappings, wie gewünscht, acht Ausgabedateien erstellt. Nähere Informationen zu diesem Methode finden Sie unter Dynamische Verarbeitung mehrerer Input- oder Output-Dateien.