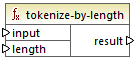
tokenize-by-length
Teilt den Input-String in eine Sequenz von Strings auf. Die Größe der einzelnen erzeugten Strings wird durch den Parameter length definiert.
Sprachen
Built-in, C++, C#, Java, XQuery, XSLT 2.0, XSLT 3.0..
Parameter
Name | Beschreibung |
|---|---|
input | Der Input-String. |
length | Definiert die Länge der einzelnen Strings in der generierten Stringsequenz. |
Beispiel
Wenn der Input-String ABCDEF und "length " 2 ist, gibt die Funktion eine Sequenz von drei Strings zurück: AB, CD und EF.

Im oben gezeigten Modell-Mapping ist das Ergebnis der Funktion eine Sequenz von Strings. Entsprechend den allgemeinen Mappingregeln wird für jedes Datenelement in der Quellsequenz ein neues Datenelement item in der Zielkomponente erstellt. Die Mapping-Ausgabe sieht daher folgendermaßen aus:
<items> |