Example: Filter with priority context
When a function is connected to a filter, priority context affects not only the function itself, but also the evaluation of the filter. The mapping below illustrates a typical case when it's required to set a priority context in order to get the correct output. You can find this mapping at the following path: <Documents>\Altova\MapForce2024\MapForceExamples\Tutorial\FilterWithPriority.mfd.
| Note: | This mapping uses XML components, but the same logic as described below applies for all other component types in MapForce, including EDI, JSON, and so on. |
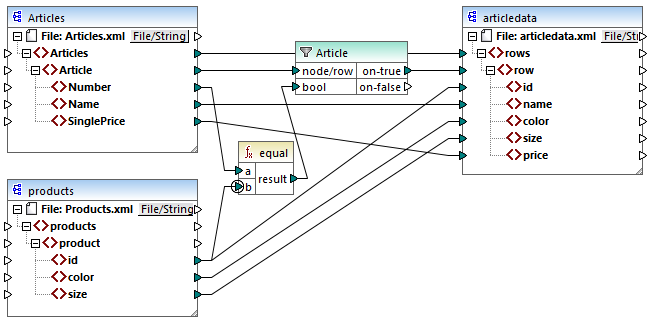
The aim of the mapping above is to copy data from Articles.xml into a new XML file with a different schema, articledata.xml. At the same time, the mapping should look up the details of each article in the Products.xml file and join them to the respective article record. Note that each record in Articles.xml has a Number and each record in Products.xml has an id. If these two values are equal, then all the other values (Name, SinglePrice, color, size) should be copied to the same row in the target.
This goal has been accomplished by adding a filter. Each filter requires a Boolean condition as input; only those nodes/rows that satisfy the condition will be copied over to the target. For this purpose, there is an equal function on the mapping. The equal function checks if the article number and product ID are equal in both sources. The result is then supplied as input to the filter. If true, then the Article item is copied to the target.
Notice that a priority context has been defined on the second input parameter of the second equal function. In this mapping, the priority context makes a big difference, and not setting it will result in incorrect mapping output.
Initial mapping: No priority context
Here is the mapping logic without priority context:
•According to the general mapping rule, for each Article that satisfies the filter condition, a new row is created in the target. The connection between Article and row (via the function and filter) takes care of this part.
•The filter checks the condition for each article. To do this, it iterates through all products, and brings multiple products in the current context.
•To populate the id on the target side, MapForce follows the general rule (for each item in the source, create an item in the target). However, as explained above, all products from Products.xml are in the current context. There is no connection between product to anywhere else in the target so as to read the id of a specific product only. As a consequence, multiple id elements will be created for each Article in the target. The same happens with color and size.
To summarize: items from Products.xml have the filter's context (which must iterate through each product); therefore, the id, color, and size values will be copied to each target row as many times as there are products in the source file, and generate incorrect output like the one below:
<rows> |
Solution A: Use priority context
The problem above was solved by adding a priority context to the function that computes the filter's Boolean condition.
Specifically, if the second input parameter of the equal function is designated as priority context, the sequence incoming from Products.xml is prioritized. This translates to the following mapping logic:
•For each product, populate input b of the equal function (in other words, prioritize b). At this stage, the details of the current product are in context.
•For each article, populate input a of the equal function and check if the filter condition is true. If yes, then put the article details as well into the current context.
•Next, copy the article and product details from the current context to the respective items in the target.
The mapping logic above produces correct output, for example:
<rows> |
Solution B: Use a variable
As an alternative solution, you could bring each article and product that matches the filter's condition into the same context with the help of an intermediate variable. Variables are suitable for scenarios like this one because they let you store data temporarily on the mapping, and thus help you change the context as necessary.
For scenarios like this one, you can add to the mapping a variable that has the same schema as the target component. On the Insert menu, click Variable, and supply the articledata.xsd schema as structure when prompted.
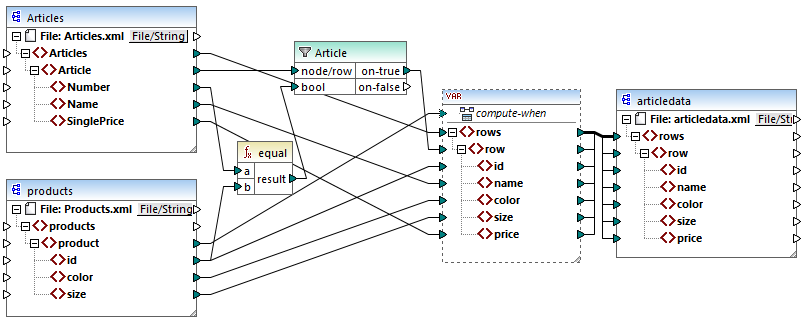
In the mapping above, the following happens:
•Priority context is not used any longer. There is a variable instead, which has the same structure as the target component.
•As usual, the mapping execution starts from the target root node. Before populating the target, the mapping collects data into the variable.
•The variable is computed in the context of each product. This happens because there is a connection from product to the compute-when input of the variable.
•The filter condition is thus checked in the context of each product. Only if the condition is true will the variable's structure be populated and passed on to the target.