Integration with RaptorXML Server
When RaptorXML is integrated into FlowForce, all the functions exposed by RaptorXML Server become available to FlowForce so that you can call them in jobs. More specifically, the RaptorXML functions exist in the /RaptorXML container of FlowForce. In case of RaptorXML+XBRL Server, the container name is /RaptorXMLXBRL.
You can call the RaptorXML functions from jobs similar to calling FlowForce built-in functions:
•In the /RaptorXML (or /RaptorXMLXBRL) container, open the function of interest, and then click Create Job. You can either reference generic functions such as /RaptorXML/valjson or release-specific functions such as /RaptorXML/2024/valjson. The differences between the two are described below.
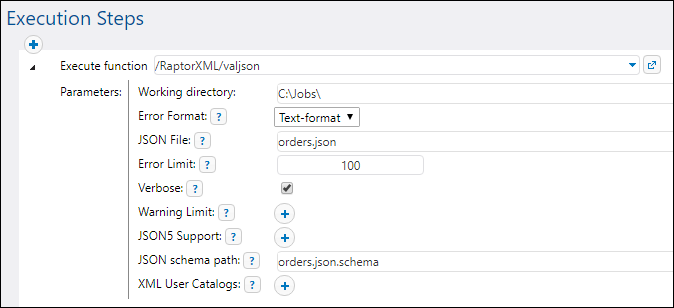
•Create a new execution step in a job, and call the desired RaptorXML function from an execution step. For example, the step below calls the valjson function:
For examples of jobs that call RaptorXML Server, see:
•Validate a Document with RaptorXML
•Validate XML with Error Logging
•Use RaptorXML to Pass Key/Value Parameter Pairs
For reference to all the RaptorXML functions, refer to the RaptorXML Server documentation (https://www.altova.com/documentation).
Manual integration
Integration between FlowForce Server and RaptorXML Server takes place automatically in many cases (for example, when you run the FlowForce Server installation on Windows and choose to install RaptorXML Server as well). However, there are also cases when manual integration between the two is necessary. Manual integration is typically required when FlowForce Server and RaptorXML Server of different versions were installed separately. For example, if the function definitions of a specific RaptorXML Server version are missing from the FlowForce Server interface even though that version of RaptorXML Server is installed, then manual integration is required.
To perform a manual integration, run the script available at the following path: {RaptorXML installation directory}\etc\functions\integrate.bat.
| Note: | On Unix systems, the script name is integrate.cs. Superuser privileges (sudo) are required to run this script. |
This script takes two arguments: the path to the FlowForce Server installation directory and the path to the FlowForce Server data directory (see FlowForce Server Application Data). When you run the script, the following happens:
•All the release-specific functions of the integrated RaptorXML Server version become available to FlowForce Server so you can call them as jobs.
•The generic (release-agnostic) RaptorXML functions are updated to point to the release-specific functions of the integrated RaptorXML version.
If the script returns errors, the function definitions of the integrated RaptorXML version are not compatible with FlowForce Server. In the unlikely event that this happens, please contact support.
Generic versus release-specific RaptorXML functions
The functions available in the RaptorXML or RaptorXMLXBRL containers are organized as follows:
•Functions from the /RaptorXML container are backward compatible down to the 2014 version of FlowForce Server (which is the first version supporting RaptorXML functions). These generic functions act as wrappers to the release-specific functions from the /RaptorXML/{Release} container. They are guaranteed to be compatible between releases but they do not provide all the features of the latest installed RaptorXML Server.
•Functions from the /RaptorXML/{Release} containers provide all the features of the corresponding RaptorXML release. These functions are compatible with FlowForce Server of the same release. However, any version of RaptorXML Server is not necessarily compatible with any version of FlowForce Server. You can check compatibility by running an integration script (as described under "Manual integration").
If a job calls a generic RaptorXML function, the function acts as a wrapper to the equivalent release-specific function of the RaptorXML Server. The selected RaptorXML release is the one that was most recently integrated into FlowForce, including manually-integrated releases. Still, as mentioned above, such calls will not benefit from the latest RaptorXML features (such as new arguments or even functions). To make use of the latest RaptorXML features from FlowForce jobs, call a release-specific function directly.
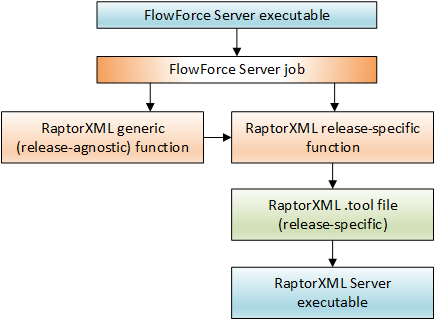
A release-specific function determines which RaptorXML .tool file should be used in order to look up the RaptorXML executable. A separate .tool file exists for each RaptorXML Server release. A .tool file instructs FlowForce Server about the location of the RaptorXML Server executable and can also be used to set environment variables, see Setting Environment Variables.
If your FlowForce jobs refer to version-specific RaptorXML functions, and if you would like to upgrade to a newer version of FlowForce Server and RaptorXML Server, you can either modify all the jobs to point to the latest release-specific RaptorXML functions, or you can map the Raptor.tool file to a newer version of the RaptorXML Server executable, as follows:
1.Copy the Raptor_<release>.tool file from {installation}\etc directory of RaptorXML Server of the latest installed release to the {configuration data}\tools directory of FlowForce Server of the same release.
2.Rename the file to match the version of the old release (the Raptor release your jobs are pointing to). For example, if the old release is RaptorXML 2017r3, then rename the file to Raptor_2017r3.tool.
If you take the mapping approach, all the existing jobs will continue to look as if they call RaptorXML 2017r3 functions, whereas the .tool file will map in fact to the latest RaptorXML Server executable.