Configure Distributed Execution
At the core of distributed execution lies the concept of execution queues.
An execution queue is a "processor" of jobs; it controls how job instances run. In order to run, every job instance is assigned to a target execution queue. The queue controls how many job instances (of all the jobs assigned to the queue) can be running at any one time and the delay between runs. By default, the queue settings are local to the job, but you can also define queues as standalone objects shared by multiple jobs. When multiple jobs are assigned to the same execution queue, they will share that queue for executing.
Queues benefit from the same security access mechanism as other FlowForce Server configuration objects. Namely, a user must have the "Define execution queues" privilege in order to create queues, see also How Privileges Work. In addition, users can view queues, or assign jobs to queues, only if they have appropriate container permissions (not the same as privileges), see also How Permissions Work. By default, any authenticated user gets the "Queue - Use" permission, which means they can assign jobs to queues. To restrict access to queues, navigate to the container where the queue is defined, and change the permission of the container to "Queue - No access" for the role authenticated. Next, assign the permission "Queue - Use" to any specific roles or users that you need. For more information, see Restricting Access to the /public Container.
Shared queues provide a flexible mechanism to control server load either on a single FlowForce machine, or when multiple FlowForce Server instances run as a cluster. Configuring load balancing is a multi-step process:
1.First, you create a queue from a dedicated page, similar to how you would create other FlowForce configuration data, such as credentials or jobs.
2.For each queue, you define its processing settings. For example, you can configure a queue to run only on master, only on workers, or both. It is also possible to define basic fallback criteria. For instance, a queue may be configured to run by default on master and all its workers; however, if all workers become unavailable, the queue will fall back to master only.
3.Edit the configuration of each job and assign the job into the custom queue created previously.
| Note: | Cross-system clusters are not supported, which means that a worker-master connection cannot be established between different OS platforms (e.g., between Linux and Windows). |
Creating queues
To create a queue as a standalone object:
1.Click Configuration, and then navigate to the container where you want to create the queue.
2.Click Create, and then Create Queue.
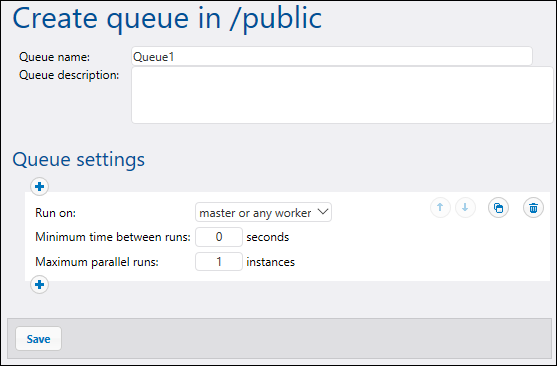
3.Enter a queue name, and, optionally, a description. For reference to all settings, see "Queue settings" below.
4.Click Save.
Queue settings
The settings available for configuration in a queue are listed below.
Queue name | Enter a name that identifies the queue. This is a mandatory field, and it must not start or end with spaces. Also, it may contain only letters, digits, single spaces, and the underscore ("_"), dash ("-"), and full stop (".") characters.
This field is applicable only if the queue is defined as standalone (not local) queue. |
Queue description | Optionally, enter a description for the queue object.
This field is applicable only if the queue is defined as a standalone (not local) queue. |
Run on | Specifies how all job instances from this queue are to be run:
•master or any worker - Job instances that are part of this queue will run indiscriminately on the master or worker machines, depending on available server cores. •master only - Job instances will run only on the master machine. •any worker only - Job instances will run on any available worker but never on master. |
Minimum time between runs | An execution queue provides execution slots, where the number of available slots is governed by the "maximum parallel runs" setting multiplied by the number of workers assigned according to the currently active rule. Each slot will execute job instances sequentially.
The "Minimum time between runs" setting keeps a slot marked as occupied for a short duration after a job instance has finished, so it will not pick up the next job instance right away. This reduces maximum throughput for this execution queue, but provides CPU time for other execution queues and other processes on the same machine. |
Maximum parallel runs | This option defines the number of execution slots available on the queue. Each slot executes job instances sequentially, so the setting determines how many instances of the same job may be executed in parallel in the current queue. Note, however, that the number of instances you allow to run in parallel will compete over available machine resources. Increasing this value could be acceptable for queues that process "lightweight" jobs that do not perform intensive I/O operations or need significant CPU time. The default setting 1 is the most conservative and is suitable for queues that process resource-intensive jobs (so as to ensure only one such "heavyweight" job instance is processed at a time).
This option does not affect the number of maximum parallel HTTP requests accepted by FlowForce Server (such as those from clients that invoke jobs exposed as Web services). For details, see Reconfiguring FlowForce Server pool threads. |
You can define multiple sets of queue settings, each with different processing requirements, by clicking the  button. To change the priority of a specific set of settings (let's call it "rule"), click the Move up
button. To change the priority of a specific set of settings (let's call it "rule"), click the Move up ![]() or Move down
or Move down ![]() buttons. For example, you can define a rule for the case when only master is available, and another rule for the case when both the master and workers are available. This enables you to create a fallback mechanism for the queue, depending on the state of the cluster at a given time. When processing queues, FlowForce Server constantly monitors the state of the cluster and "knows" if any worker is unavailable. So, if you defined multiple queue settings rules, FlowForce Server evaluates them in the defined order, top to bottom, and picks the first rule that has at least one cluster member assigned according to "run".
buttons. For example, you can define a rule for the case when only master is available, and another rule for the case when both the master and workers are available. This enables you to create a fallback mechanism for the queue, depending on the state of the cluster at a given time. When processing queues, FlowForce Server constantly monitors the state of the cluster and "knows" if any worker is unavailable. So, if you defined multiple queue settings rules, FlowForce Server evaluates them in the defined order, top to bottom, and picks the first rule that has at least one cluster member assigned according to "run".
As an example, let's consider a setup where the cluster includes one master and four worker machines. The queue settings are defined as shown below:
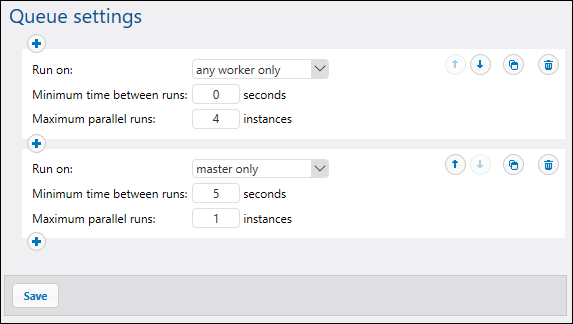
With the configuration illustrated above, FlowForce would process the queue as follows, depending on the current state of the cluster:
•If all workers are available, the top rule matches and will be applied. Namely, up to 16 job instances are permitted to run simultaneously (4 instances for each worker). The minimum time between runs is 0 seconds.
•If only three workers are available, the top rule still matches. Namely, up to 12 job instances are permitted to run simultaneously, and the minimum time between runs is 0 seconds.
•If no workers are available, the second rule matches and will be applied. Namely, up to 1 instance is permitted to run simultaneously, and the minimum time between runs is 5 seconds.
This kind of configuration makes execution still possible in the absence of workers. Notice that the "master only" rule is stricter (1 instance only, and 5 seconds delay between runs) so as not to take away too much processing power from the master machine when all workers fail.
Assigning jobs into queues
Once you have configured the queue, you will need to edit the configuration of each job that you want to assign to this queue. You will find the queue settings in the job configuration page, in the "Queue Settings" group:
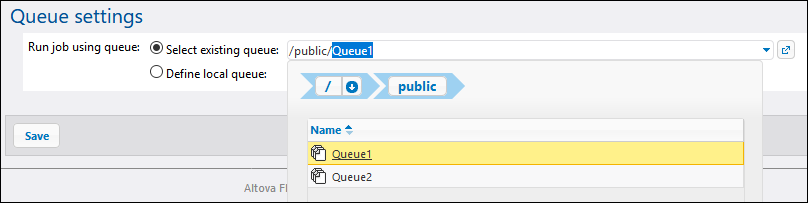
| Note: | If you select Define local queue, FlowForce Server will assign, at job runtime, instances of this job into a default queue, with the local settings you specify, see also Defining Queue Settings. Local queues do not support distributed processing. The queue must be created standalone (external to the job) in order to benefit from distributed processing. |