Node Functions Simplify Mapping Hierarchical Data Structures
MapForce node functions simplify mapping hierarchical data such as XML nodes or CSV, JSON, EDI, or database fields by permitting users to define a data processing function at the node level and apply it recursively to all descendant items.
Similarly, default values can also be assigned to nodes and automatically applied to descendants.
Defaults and node functions are particularly useful when a data mapping and transformation task requires the same processing logic for multiple descendant items in a structure, for example:
- Replace null values with some other value, recursively for all descendant items
- Replace a specific value (for example, "N/A") with some other value recursively for all descendant items
- Replace all database null values when reading from a database table
- Trim all trailing spaces for all values from a source database
- Append a custom prefix or suffix to all values written to a target file or database
- Formatting of output values
- And many others
Defaults and node functions simplify mapping hierarchical data by eliminating need to copy-paste the same function multiple times into a mapping. Repeating the same function unnecessarily clutters the mapping layout and makes it more difficult to understand or revise.
Let’s look at an example.
The mapping from XML to CSV shown below is the OrderinUSD.mfd example provided in the MapForce Examples project and illustrates both the efficiency and flexibility of node functions.
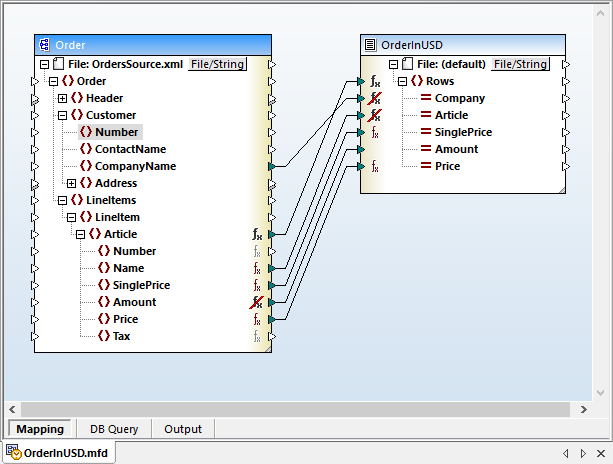
This example maps an order from a source XML file to output a CSV text. Additional requirements are the Price element in the source in euros must be converted to dollars, and the name of each item ordered must be converted to all capital letters.
A node function achieves both requirement and is indicated by the function symbol to the right of the Article node. Double-clicking the function symbol opens the node functions definition dialog above the mapping pane:
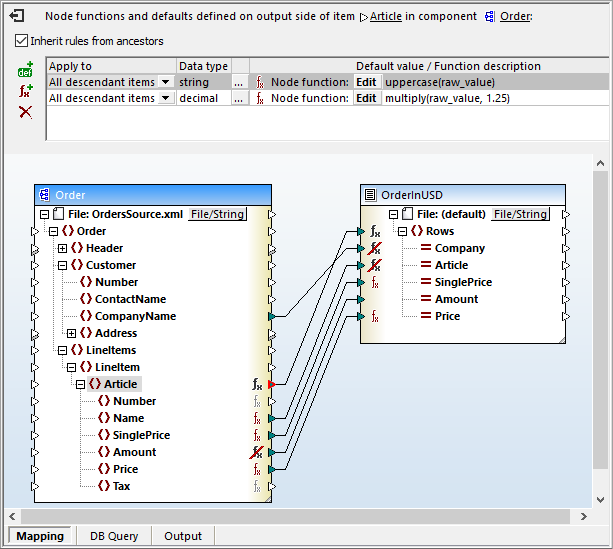
This single node function combines two MapForce operations to perform both the required currency and string conversions. More rows can be added to the node function by clicking the icons at the left for a default value or function row.
The first field in each row defines whether the row applies to a single child level or all descendants of the parent mode.
The second field defines what data type will be modified. Clicking the … button opens the dialog shown here to choose the datatype:
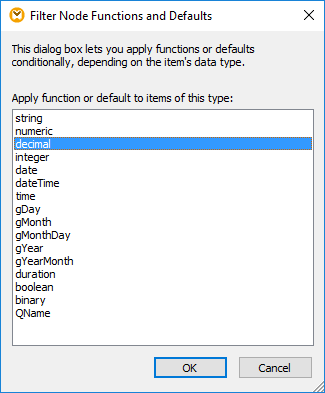
Our example contains rows for only two datatypes, but a node function could be defined with rows for every possible datatype. For each child of the parent node, the row with the matching datatype will be executed.
The third field specifies whether the row uses a function or a default value. In either case, the Edit button opens that row for definition:
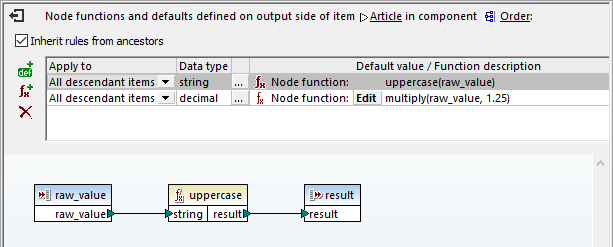
Defining a Node function row is accomplished by dragging functions from the Function Library window and/or defining constants for the function and connecting them to sources and outputs.
The Amount element in the example input file is actually the quantity ordered for each Article and should not be multiplied by the currency conversion factor defined in the node function. It’s easy to define Amount as an exception by right-clicking the corresponding function symbol and deselecting Inherit Output Node Functions from the context menu.
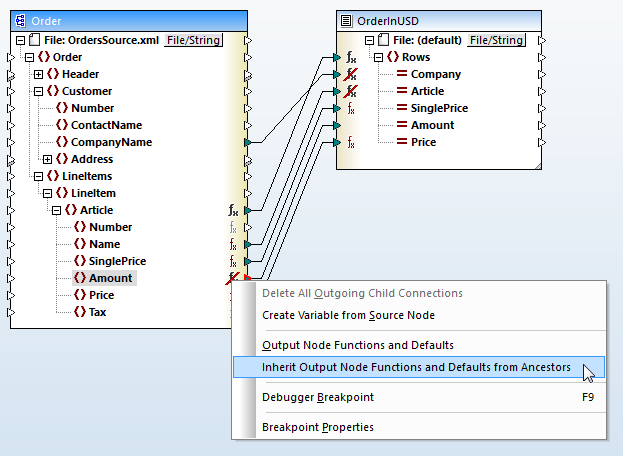
There is one more requirement for the CSV output file. The individual item price and subtotal price for each Article must be provided with a leading dollar sign. The output file definition shows the SinglePrice and Price columns are defined as string data and MapForce automatically converts decimal values from the source to strings.
Adding the leading dollar signs is accomplished by an additional node function applied to the Rows node of the output component, as seen here:
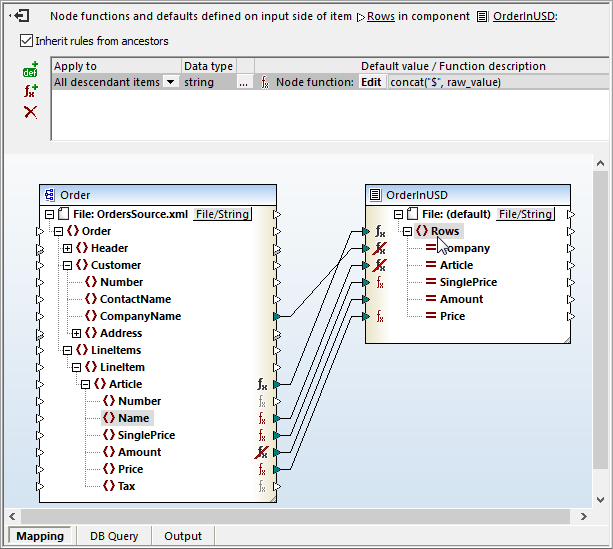
To prevent this node function from applying to all columns containing string data, exceptions were applied to the Company and Article columns. Now the example for mapping hierarchical data with node functions is complete.
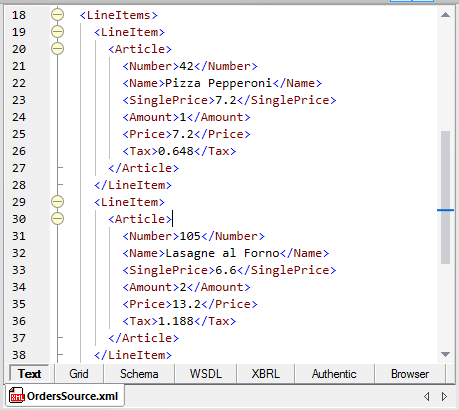
Like other MapForce examples, a source data file is provided for this mapping to demonstrate the results. Here is the source file viewed in the XMLSpy XML editor:
MapForce mappings that require repetitive transformation, such as for an online order processing system, can be automated by MapForce Advanced Server. To execute the mapping for testing or one-time conversion, simply click the Output button under the mapping design window.
Either way, our example mapping produces this result:

Along with the data mapping described in this post, MapForce includes several other node function examples. The MapForce integrated help system even includes a step-by-step tutorial to build a node function mapping from scratch.
To see for yourself how node functions simplify mapping hierarchical data, click here to download a fully-functional MapForce free trial.
UPDATE: Check out this post for another strategy to apply node functions based on node metadata such as the node name, node length, precision of the node’s data type, customized node annotations, and more.